


Oggi il settore manifatturiero genera costantemente volumi di dati: anche la velocità, la varietà e la complessità dei dati sono in aumento. Tuttavia, solo coloro che sanno come gestire correttamente i dati e convertirli in informazioni possono aggiungere valore reale. Inoltre, i dati rafforzano il processo decisionale e convalidano una linea d’azione prima di impegnarsi in esso.
In questo articolo, si spiega come le statistiche possono aiutare a capire i dati generati da una linea di assemblaggio e come sia stato utilizzato il software open source R per analizzare i dati e l’applicazione web R Shiny per riassumere tutte le analisi. Nel mondo competitivo e tecnologico di oggi, è obbligatorio rendere le nostre risorse più intelligenti utilizzando la tecnologia e l’innovazione open source. Abbiamo una grande occasione di far “parlare le machine” e farci indicare la via da seguire per le nostre decisioni. La tecnologia ci mette a disposizione, ogni giorno di più, strumenti che lasciano a sensori, reti e algoritmi il compito di raccogliere e analizzare i dati e all’uomo quelli di giudizio e comprensione.



Breve introduzione del prodotto e della linea di assemblaggio, con spiegazioni da foto
Di seguito è riportata la fotografia della linea di montaggio, che viene presa come riferimento per questo articolo, costituita da sei stazioni e che produce pezzi per settore automotive. Si tratta di una linea di assemblaggio che utilizza principalmente la tecnologia di avvitamento e test per assemblare il prodotto.

Breve introduzione della piattaforma utilizzata per l’analisi dei dati
Il software, che è stato utilizzato per analizzare i dati, è il software open source R e pacchetto R Shiny utilizzato per l’applicazione web. L’architetto di base della piattaforma di analisi dei dati ha mostrato di seguito.
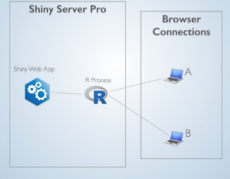
Prima di proseguire con l’articolo, si dovrebbe cercare di comprendere meglio le Statistiche e i Dati.
Statistica, che cos’è la Statistica?

La statistica è una raccolta di metodi che ci aiutano a descrivere, riassumere, interpretare e analizzare i dati. La statistica traduce i dati in conoscenza e comprensione del mondo che ci circonda. In breve, la statistica è l’arte e la scienza dell’apprendimento dai dati.
Si ha già un senso di cosa significa la parola Statistica. Si applica la statistica agli eventi sportivi (numero di punti segnati da ogni giocatore in una squadra di basket), all’economia (reddito medio, tasso di disoccupazione) alle opinioni, credenze e comportamenti. In questo senso, una statistica è semplicemente un numero calcolato dai dati. Non importa quale sia la questione di interesse, è importante raccogliere i dati in modo da consentire la sua analisi.
Dati, che cosa sono i dati?
La vita sarebbe poco interessante se tutti guardassero nello stesso modo, mangiassero lo stesso cibo e avessero gli stessi pensieri. Fortunatamente, c’è variabilità ovunque e i metodi statistici forniscono modi per misurare e comprendere questa variabilità. Ad esempio, c’è variabilità tra i compagni di classe in peso, in GPA, nello sport preferito e anche in molti altri aspetti. Le caratteristiche, che si osservano in questo studio per capire questa variabilità vengono chiamate Variabili. Qualsiasi informazione che ci interessa può essere acquisita in una variabile di questo tipo. Ad esempio, se le nostre osservazioni si riferiscono a esseri umani, la variabile può descrivere lo stato civile, sesso, età, o qualsiasi altra cosa, che può riguardare una persona. Le variabili possono essere Qualitative (in categorie) o Quantitative (numeriche).
- Variabili qualitative: Queste sono le variabili, che non possono essere ordinate in modo logico o naturale. Per esempio,
- il colore dell’occhio,
- il nome di un partito politico
- il tipo di trasporto utilizzato per recarsi al lavoro
- Variabili Quantitative: Una variabile è Quantitativa se le osservazioni su di essa prendono valori numerici che rappresentano grandezze diverse della variabile. Per le variabili Quantitative, le caratteristiche chiave da descrivere sono il centro e la variabilità (talvolta definita “spread”) dei dati. Per esempio, qual è una tipica quantità annuale di precipitazioni? C’è molta variazione da un anno all’altro?
Ogni valore che può assumere una variabile quantitativa è un numero e le variabili quantitative vengono classificate come Discrete o Continue.
- Discreto: una variabile quantitativa è discreta se i suoi possibili valori formano un insie me di numeri separati. Esempi di variabili discrete sono il numero di animali domestici in una famiglia, il numero di figli in una famiglia. I valori possibili sono numeri separati, ad esempio [0, 1, 2, 3, 4, . . .]
- Continuo: Una variabile quantitativa è continua se i suoi valori possibili formano un intervallo. Esempi di variabili continue sono altezza, peso, età. Le variabili continue hanno un continuum infinito di valori possibili.
In questo articolo verranno utilizzate le variabili Quantitative per l’analisi statistiche. Questa analisi verrà eseguita sul set di dati di una delle linee di assemblaggio che assemblano la pompa con 5 diverse stazioni e ogni stazione genera alcuni dati relativi al processo o al prodotto. L’analisi stastica aiuterà a capire il comportamento di qualsiasi processo, anche a supporto di dati interni per estrarre informazioni preziose. Inoltre, queste preziose informazioni aiutano a prendere la decisione giusta in modo proattivo e questo può aiutare un’azienda ad essere più efficiente e risparmiare soldi.
Architettura dei dati
In figura 3 viene riportato la nostra architettura tipica di raccolta automatica e analisi dati utilizzando una tabella di SQL Server, in cui essi si aggiornamento in modo dinamico nel tempo. Inoltre, tutta l’analisi dei dati è stata eseguita utilizzando il linguaggio R, che è un software open source, e tutta l’applicazione web è stata effettuata utilizzando la libreria R Shiny.
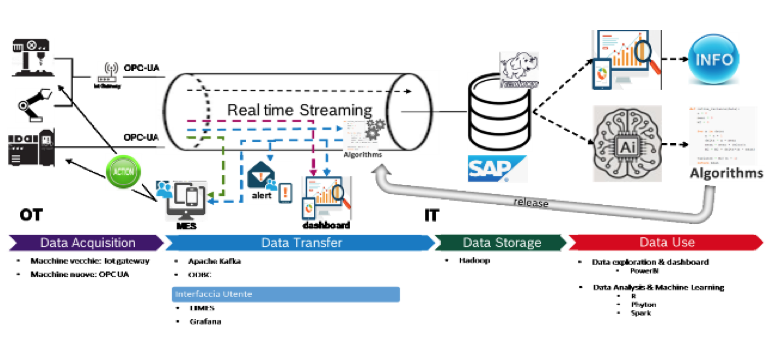
Analisi dei dati
Passaggio 1: Creazione del set di dati
Esiste un modo unico in cui i dati vengono preparati e raccolti per essere utilizzati nelle analisi statistiche. I dati vengono archiviati in una matrice di dati (set di dati) con colonne p e n righe (vedere Fig. 2). Ogni riga corrisponde ad un’osservazione e ogni colonna si comporta come una variabile.

In questo esempio la matrice di dati, che si sta usando, è simile a quella della figura 3. Si tratta di una tabella dinamica, che viene aggiornata in SQL Server usando il concetto di architettura dei dati, a cui precedentemente si è fatto riferimento. Ogni giorno vengono aggiunte circa 4000 righe, costituite principalmente da variabili quantitative, generate dal processo. Queste variabili quantitative garantiscono le prestazioni del prodotto e del processo. La matrice è costituita anche dalla variabile Date, che ci aiuterà a vedere la variazione rispetto al tempo.
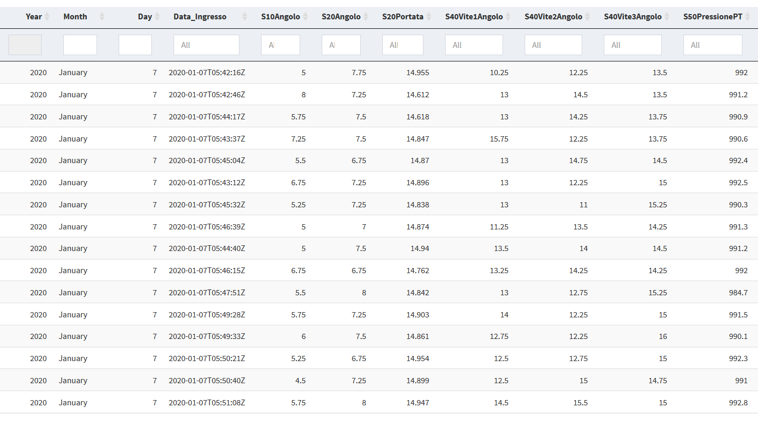
Passaggio 2: Rappresentazione grafica di una variabile
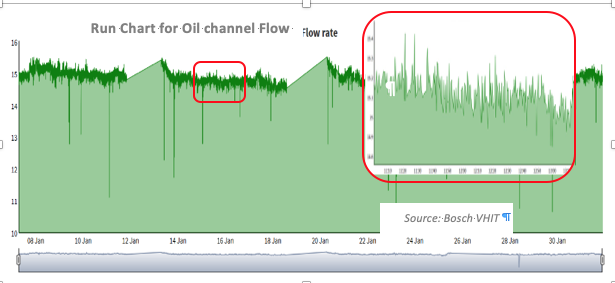
- Run Chart: Un grafico Run è un grafico a linee di dati tracciati nel tempo. Raccogliendo e tracciando i dati nel tempo, è possibile trovare tendenze o modelli nel processo. Poiché non si utilizzano limiti di controllo, i grafici in esecuzione non sono in grado di stabilire se un processo è stabile. Tuttavia, possono mostrare come viene eseguito il processo. Il grafico di esecuzione può essere uno strumento prezioso all’inizio di un’analisi, in quanto rivela informazioni importanti su un processo prima di passare ad un’analisi più approfondita per vedere la variabilità di processo/prodotto.
- Histogram: Se una variabile è costituita da un numero elevato di valori diversi, anche il numero di categorie utilizzate per costruire grafici a barre sarà grande. Pertanto, un grafico a barre potrebbe non fornire un riepilogo chiaro quando applicato a una variabile continua. Invece, un istogramma è la scelta appropriata per rappresentare la distribuzione di valori di variabili continue. Si basa sull’idea di classificare i dati in diversi gruppi e tracciare le barre per ogni categoria con altezza , dove dj indica la larghezza dell’intervallo o della categoria della classe.
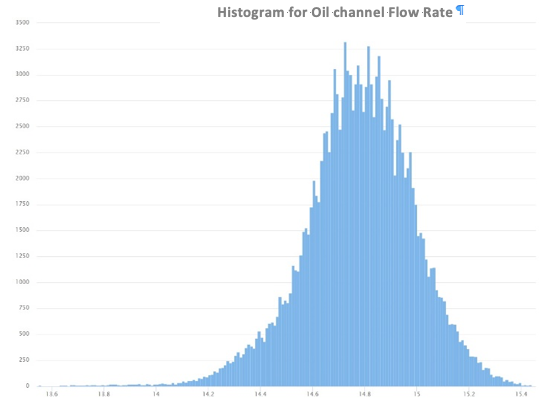
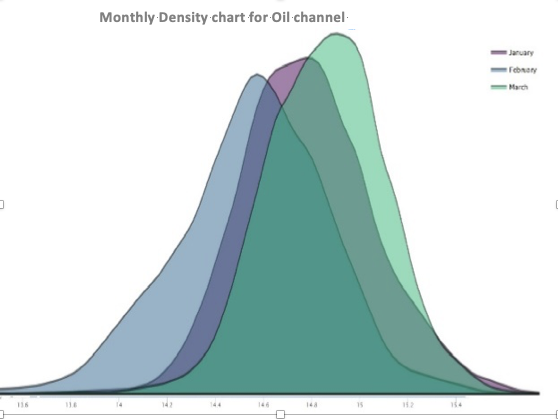
- Density Plot: Uno svantaggio degli istogrammi è che i dati continui sono classificati artificialmente. La scelta delle classi di intervallo è cruciale per l’aspetto finale del grafico. Un modo più elegante per affrontare questo problema è quello di appianare l’istogramma nel senso che ogni osservazione può contribuire a classi diverse con pesi diversi e la distribuzione è rappresentata da una funzione continua piuttosto che da una funzione a gradino. Un vantaggio rispetto ai diagrammi di densità rispetto agli istogrammi è che sono migliori nel determinare la forma di distribuzione perché non sono influenzati dal numero di bin utilizzati (ogni barra utilizzata in un tipico istogramma). Un istogramma composto da soli 4 contenitori non produrrebbe una forma di distribuzione abbastanza distinguibile come farebbe un istogramma a 20 scomparti. Tuttavia, con i grafici di densità, questo non è un problema. Nel grafico della densità sottostante si può anche osservare la variazione del processo con risposta al tempo (3 mesi).
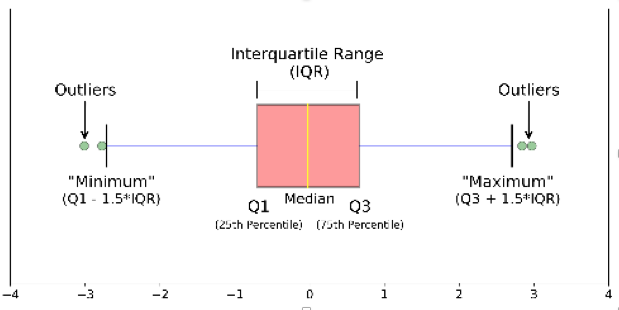
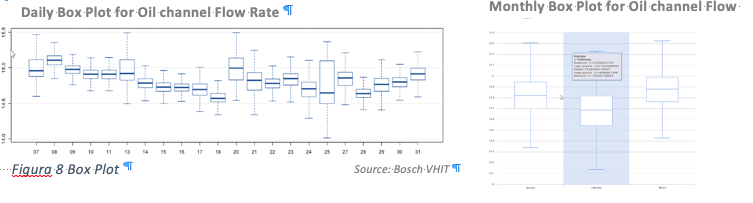
- Box Plot: Un grafico semplice e potente è il diagramma a riquadri che riassume la distribuzione di una variabile continua usando i suoi valori mediano, quartile, minimo, massimo ed estremo. la figura a sinistra mostra un tipico diagramma a riquadri. La lunghezza verticale del riquadro è l’intervallo interquartile che mostra la regione che contiene il 50% dei dati. L’estremità inferiore della casella fa riferimento al primo quartile e l’estremità superiore della casella fa riferimento al terzo quartile. La linea spessa nella casella è la mediana. Diventa subito chiaro che la casella indica la simmetria dei dati: se la mediana si trova al centro della casella, i dati dovrebbero essere simmetrici, altrimenti sono inclinati. I baffi alla fine della trama segnano i valori minimo e massimo dei dati. Osservando il diagramma a riquadri nel suo insieme ci viene spiegato la distribuzione dei dati, l’intervallo e la variabilità delle osservazioni. A volte, può essere consigliabile capire quali valori sono estremi, nel senso che sono “lontani” dal centro della distribuzione. In molti pacchetti software, incluso R, i valori sono definiti estremi se sono maggiori di 1,5 volte di lunghezza dal primo o terzo quartile. A volte, sono chiamati valori anomali.
Step 3. Analisi delle capacità di processo
Fino ad ora, abbiamo compreso la variazione di qualsiasi variabile rispetto al tempo (Run Chart, Histogram and Density Chart) o rispetto ad alcuni parametri statistici (Density Chart e Box Plot) ma non abbiamo testato le prestazioni del processo rispetto alle specifiche. L’analisi della capacità di processo è un insieme di strumenti utilizzati per scoprire se un determinato processo soddisfa un insieme di limiti di specifica. In altre parole, misura il rendimento di un processo.
Per questo generalmente utilizziamo l’indice di capacità del processo per conoscere lo stato del processo. Gli indici di capacità confrontano direttamente le specifiche del cliente con le prestazioni del processo. Si basano sul fatto che i limiti naturali o i limiti effettivi di un processo sono quelli tra la media e ± 3 deviazioni standard. Si può dimostrare che il 99,7% dei dati è contenuto entro questi limiti.
Cp sta per capacità di processo ed è una semplice misura della capacità di un processo. Ci dice quanto potenziale ha il sistema di soddisfare i limiti di specifica superiore e inferiore. La capacità di un processo (Cp) viene calcolata usando la formula
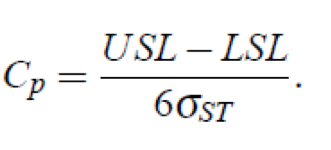
Questa formula non ci consente di verificare se il processo è centrato nella media (che è desiderabile). Per risolvere questo problema, utilizziamo l’indice di capacità rettificato (Cpk):
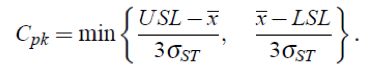
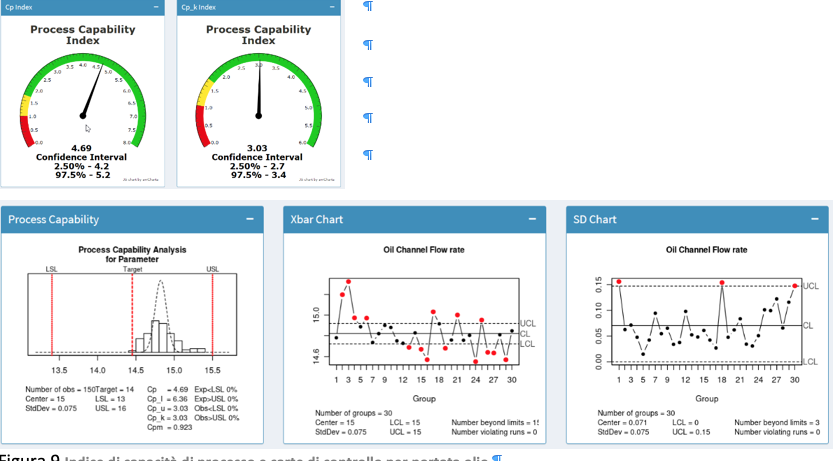
Puoi testare quanto è centrato un sistema confrontando Cp con Cpk. Se un processo è centrato sul suo obiettivo, questi due saranno uguali. Maggiore è la differenza tra Cpk e Cp, più decentrato è il processo. Cpk sta per indice di capacità del processo e si riferisce alla capacità di un determinato processo di ottenere risultati nell’ambito di determinate specifiche. Nella produzione, descrive la capacità di un produttore di produrre un prodotto che soddisfi le aspettative dei consumatori, all’interno di una zona di tolleranza. Nel nostro esempio è possibile visualizzare la seguente visualizzazione dell’analisi della capacità del processo.
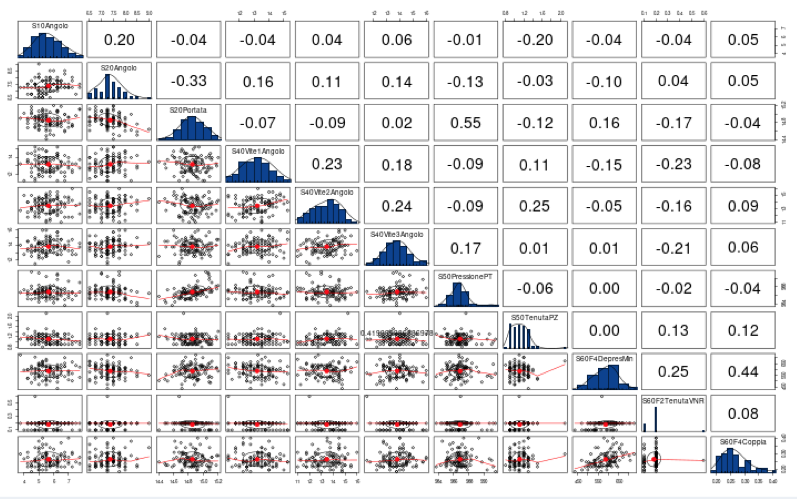
Step 4. Correlation Matrix (Associazione tra variabili continue)
Un modo semplice per riassumere graficamente l’associazione tra due variabili continue è quello di tracciare le osservazioni accoppiate delle due variabili in un sistema di coordinate bidimensionale. Se n osservazioni disponibili per due variabili continue X e Y sono disponibili come (xi, yi), i = 1, 2,. . . , n, quindi tutte queste osservazioni possono essere tracciate in un singolo grafico. Questo grafico è chiamato grafico a dispersione. Tale trama rivela possibili relazioni e tendenze tra le due variabili.
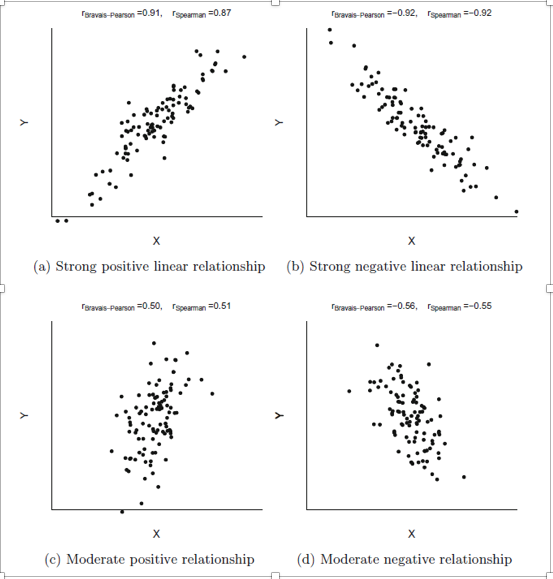
La figura (a) mostra i valori crescenti di Y per aumentare i valori di X. Chiamiamo questa relazione un’associazione positiva. La relazione tra X e Y è quasi lineare perché tutti i punti si trovano attorno a una linea retta.
La Figura (b) mostra i valori decrescenti di Y per aumentare i valori di X. Chiamiamo questa relazione un’associazione negativa.
La figura (c) ci dice lo stesso della figura (a), tranne per il fatto che l’associazione positiva è più debole. La figura (d) ci dice lo stesso della figura (b), tranne per il fatto che l’associazione negativa è più debole.
Supponiamo che due variabili X e Y siano misurate su una scala continua e siano linearmente correlate come Y = a + b X dove a e b sono valori costanti. Il coefficiente di correlazione r (X, Y) = r misura il grado di relazione lineare tra X e Y. Il coefficiente di correlazione è indipendente dalle unità di misura di X e Y. Ad esempio, se qualcuno misura l’altezza e il peso in metri e chilogrammi rispettivamente e un’altra persona li misura rispettivamente in centimetri e grammi, quindi il coefficiente di correlazione tra le due serie di dati sarà lo stesso. Il coefficiente di correlazione è simmetrico, ovvero r (X, Y) = r (Y, X). I limiti di r sono −1 ≤ r ≤ 1. Se tutti i punti in un diagramma a dispersione si trovano esattamente su una linea retta, la relazione lineare tra X e Y è perfetta e | r | = 1. Se la relazione tra X e Y è (i) perfettamente lineare e crescente, allora r = +1 e (ii) perfettamente lineare e decrescente, quindi r = −1. I segni di r determinano quindi la direzione dell’associazione. Se r è vicino a zero, allora indica che le variabili sono indipendenti o che la relazione non è lineare. Si noti che se la relazione tra X e Y non è lineare, il grado di relazione lineare può essere basso e r è quindi vicino a zero anche se le variabili non sono chiaramente indipendenti. Nota che r (X, X) = 1 e r (X, −X) = −1. Se mettiamo insieme tutte le variabili continue e misuriamo l’associazione tra loro, allora appare come di seguito.
Lasciamo lavorare gli algoritmi
Capita l’importanza dei dati e della loro possibilità di farci “vedere” cosa accade ai nostri processi, la tecnologia ci offre la possibilità di far “parlare” le macchine. Con l’architettura dati di fig. 3 siamo nelle condizioni di raccogliere in automatico i dati, inserendo opportuni sensori, di trasferirli e di analizzarli. E qui c’è il grande valore aggiunto: agli operatori, agli ingegneri non è più richiesta la raccolta dati e magari la loro elaborazione con vecchi fogli excel. Tutto questo è fatto dal sistema di raccolta e dagli algoritmi di cui si è parlato. Ai tecnici, quindi, rimane il compito di interpretazione e giudizio delle informazioni, agli algoritmi quello di esecuzione. Quest’ultima, evidentemente molto più veloce rispetto al calcolo che può fare un uomo.
E il tempo che risparmiamo nella raccolta e nell’eseguire calcoli dove va? Va in produttività.
Se lascio l’uomo a gestire attività di più alto valore posso avere decisioni più veloci e con poca probabilità di errore. Riconoscere un trend o, meglio ancora, prevederlo con un po’ di intelligenza artificiale che analizza i dati prodotti ci consente di aumentare, facilmente, l’efficienza degli impianti con variazioni anche a due cifre. Provate a pensare ad un vostro impianto dove potete avere le caratteristiche di cui sopra (e molte altre ancora) continuamente aggiornate: voi dovrete solo prendere decisioni e indirizzare meglio le attività di correzione.
Anzi, impianti e macchine dotate già di retroazione possono correggere eventuali derive senza l’intervento dell’uomo.
Ma cosa ci serve allora per implementare questi sistemi?
Innanzitutto una solida cultura di base: di meccanica, di fisica, di gestione processi, di ingegneria. Perché è vero che lasciamo la raccolta dati ai sensori, la loro trasmissione alle reti e la trasformazione dei dati in informazione agli algoritmi ma dobbiamo sapere quali dati prendere e come interpretare la loro correlazione. Poi ci vuole tanta consapevolezza e passione per le tecnologie. Oggi abbiamo strumenti a disposizione che si arricchiscono di giorno in giorno e spingono sempre più in avanti i limiti delle cose che si possono fare. E, attenzione, non solo sui nuovi impianti; tutto quello di cui abbiamo parlato si può tranquillamente applicare ad impianti esistenti e datati.
Il Revamping Digitale non solo è possibile ma è necessario, specie in momenti di crisi economica perché anche macchine non nuove possono dare prestazioni eccellenti: basta farle parlare.
Bosch Vhit: la mobilità elettrica fa crescere l’industria meccatronica. Intervista con Corrado La Forgia, amministratore delegato e direttore industriale
Conclusione
L’analisi dei dati è definita come un processo di pulizia, trasformazione e modellazione dei dati per scoprire informazioni utili per il processo decisionale aziendale. Lo scopo dell’analisi dei dati è quello di estrarre informazioni utili dai dati e prendere la decisione in base all’analisi dei dati. In questo articolo, ci concentriamo principalmente sull’analisi statistica che comprende raccolta, analisi, interpretazione, presentazione e modellizzazione dei dati. Analizza un insieme di dati o un campione di dati. L’analisi dei dati può trattarli in diversi modi, ad esempio tracciandoli e trovando correlazioni che magari non conoscevamo.
Lasciamo quindi “parlare” le nostre macchine, facciamoci dire cosa possiamo e dobbiamo fare per loro. Lasciamo fare il lavoro “sporco” a sensori e algoritmi e rimettiamo l’uomo a fare quello che sa fare meglio: pensare, creare, risolvere. Raccoglieremo frutti preziosi.
Quello che avete visto è realtà che si spinge ogni giorno un po’ in avanti in Bosch VHIT.
E non pensate che l’analisi dei dati si fermi qui. Siamo solo all’inizio.
References
- Luca Beltrametti, Nino Guarnacci, Nicola Intini & Corrado La Forgia. La fabbrica connessa. La manifattura italiana (attra)verso industria 4.0.
- Franklin, Alan Agresti & Christine A. Statistics: The Art and Science of Learning from Data (3rd Edition).
- Tomek, Randall Schumacker & Sara. Understanding Statistics Using R .
- Gareth James, Daniela Witten, Trevor Hastie & Robert Tibshirani. An Introduction to Statistical Learning: with Applications in R (Springer Texts in Statistics).
- [Online] R Studio. https://rstudio.com/products/shiny/shiny-server/.
- [Online] https://rstudio.com/products/rstudio/.







")

