Quando si va a chiedere cosa caratterizza l’Industria 4.0, si ricevono svariate risposte, che chiamano in causa la robotica, l’Internet of Thing, l’Intelligenza Artificiale. Ma il vero carattere unificante del paradigma Industry 4.0 è rappresentato dal dato. Raccogliere, filtrare, trasmettere, memorizzare, analizzare i dati provenienti dalle macchine è il vero punto focale, è ciò che differenzia la quarta rivoluzione industriale dalle precedenti. Il fatto è che a sentire i teorici è tutto facile: raccogli i dati dei sensori, li analizzi e il computer ti dice se e quando la tua macchina è a rischio guasto, o in quali fasi non è efficiente, o quando è il momento migliore per fare manutenzione. Nella realtà, non è tutto così semplice. Anzi, passare da collezionare milioni di letture di un sensore di vibrazioni a una previsione attendibile di un possibile guasto è maledettamente complicato.
Per arrivarci, bisogna implementare una serie di meccanismi che partono dall’acquisizione del dato dalla macchina, dalla sua pulizia e manipolazione, e proseguono con la creazione di algoritmi di analisi che permettano di correlare i dati raccolti con lo stato della macchina stessa, in modo da poter formulare una “diagnosi” sullo stato del macchinario, seguita da una “prognosi” ovvero un’informazione su come presumibilmente questo stato si evolverà, e infine dalla generazione di avvisi e allarmi in base ai risultati. L’implementazione di questi meccanismi segue generalmente uno schema ben definito, per esempio quello descritto nel protocollo ISO 13374-1 (ma ce ne sono anche altri). Tuttavia, l’architettura vera e propria varia da caso specifico a caso specifico – difficilmente due progetti Industria 4.0 saranno uguali – e richiede per essere realizzata team di progettisti con competenze multi-settoriali: esperti di automazione (per il sistema di rilevamento), matematici e informatici (per gli algoritmi di analisi), ingegneri manutentori e ancora informatici e matematici per le successive fasi di determinazione dello stato, diagnosi, prognosi e generazione e gestione allarmi.



Ora, abbiamo una notizia buona e una ottima. Quella buona è che la complessità del sistema è affrontata essenzialmente da chi lo progetterà, programmerà e implementerà; quella ottima è che l’utente, ovvero chi gestisce il macchinario, la linea di produzione, o anche un gruppo di fabbriche controllate dallo stesso sistema, potrà tenere sotto controllo la situazione per mezzo di semplici dashboard personalizzate, grazie alle quali potrà avere visibilità sullo status, sulle previsioni, sugli allarmi, sui Kpi di efficienza, sui consumi, eccetera. Ma, torniamo a ripetere, questa estrema facilità d’uso è il risultato finale di un lavoro di progettazione complesso, spesso lungo, ma assolutamente indispensabile. Un lavoro che prevede anche l’utilizzo dei paradigmi più recenti messi a disposizione dall’informatica, dal Cloud al Fog Computing, fino ad arrivare ai Data Lake. Del viaggio e della trasformazione dei dati dalla macchina, alla linea, al plant, fino all’impiego a livello aziendale e di business si è parlato in un recente workshop intitolato “Dal dato di macchina e di fabbrica, al dato d’impresa”, durante il quale gli esperti del Politecnico di Milano Adalberto Polenghi (assistant professor, specialista in ingegneria gestionale/ingegneria industriale, responsabile area 5 del Made) e Pierluigi Plebani (professore associato, specialista in sistemi informativi, responsabile area 6 del Made) hanno sviscerato l’argomento nei suoi aspetti più criptici, sfruttando poi le stazioni di dimostrazione tecnologica presenti al Made per illustrare in modo concreto alcuni esempi pratici dei concetti esposti.
Perché acquisire dati?

Il primo e più comune motivo per acquisire dati di funzionamento da un macchinario è legato alla necessità di ottimizzarne la manutenzione. Nello sviluppo “storico” dei sistemi di manutenzione, si è passati dalla manutenzione correttiva (sostituire il cuscinetto che si è guastato) a quella preventiva pianificata (sostituire il cuscinetto ogni 6 mesi), per poi evolversi verso forme proattive come la manutenzione su condizione (se rilevo un rumore anomalo, cambio il cuscinetto) e, con la disponibilità di dati ed algoritmi di analisi, a forme di manutenzione predittiva (i dati analizzati mi dicono che il cuscinetto si romperà fra 5 giorni e posso decidere qual è il momento migliore per cambiarlo). È chiaro che l’ultimo approccio, quello predittivo, è quello che ottimizza la gestione del sistema: permette di minimizzare gli interventi, di eseguirli riducendo al mimino i fermi di produzione, e di decidere le strategie di intervento in base a cosa vogliamo ottimizzare (tempo di funzionamento, qualità della produzione, consumi…). Ma fin qui parliamo della raccolta di dati che riguardano un solo macchinario. Cosa succede quando i macchinari in una linea di produzione sono più di uno? Cosa succede quando ci sono più linee di produzione in una fabbrica? Cosa succede quando un’azienda possiede più fabbriche che vanno gestite in modo coordinato? Ebbene, in questo caso i dati salgono di livello, per così dire. «Passare dal dato di macchina al dato di fabbrica vuol dire, sostanzialmente, passare da un’analisi dei dati riferiti a una sola macchina, a usare quei dati per gestire processi nei quali il cuore non è la singola macchina ma più macchine» spiega Polenghi.
Per esempio, il processo di produzione necessita sì dei dati (salute, occupazione…) della singola macchina, ma ha bisogno anche di un’informazione complessiva su tutto il parco macchine che concorrono a quella produzione: come si stanno comportando, se stanno subendo delle deviazioni, e se sono in modalità di allarme. Questo consente di ottimizzare la gestione della produzione, con l’obiettivo di garantire una certa continuità operativa. «Dalla singola fabbrica, o dalla singola linea all’interno della fabbrica, ci possiamo spostare verso una visione multipla, dove i dati aumentano, soprattutto in volume, ma anche in varietà – prosegue Polenghi – avremo quindi diverse tipologie di dati, veloci o lenti, che arrivano da vari dipartimenti, quindi non soltanto dalle macchine ma anche dalla supply chain, dal customer service eccetera. Tutti questi dati, che magari arrivano da multiple fabbriche, vanno armonizzati e gestiti nel miglior modo possibile». Questo percorso del dato, quindi, permette di allargare mano a mano lo “scope” ovvero l’ambito di utilizzo del dato stesso. Se il dato di macchina consente di monitorare il singolo macchinario, quando viene aggregato con quelli provenienti dalle altre macchine può essere usato per controllare il processo produttivo, e quando combinato con i dati provenienti da altri dipartimenti può acquisire una valenza in ottica business. Per esempio, conoscendo lo stato della mia supply chain posso schedulare la manutenzione anche in base alle previsioni di consegna delle materie prime.
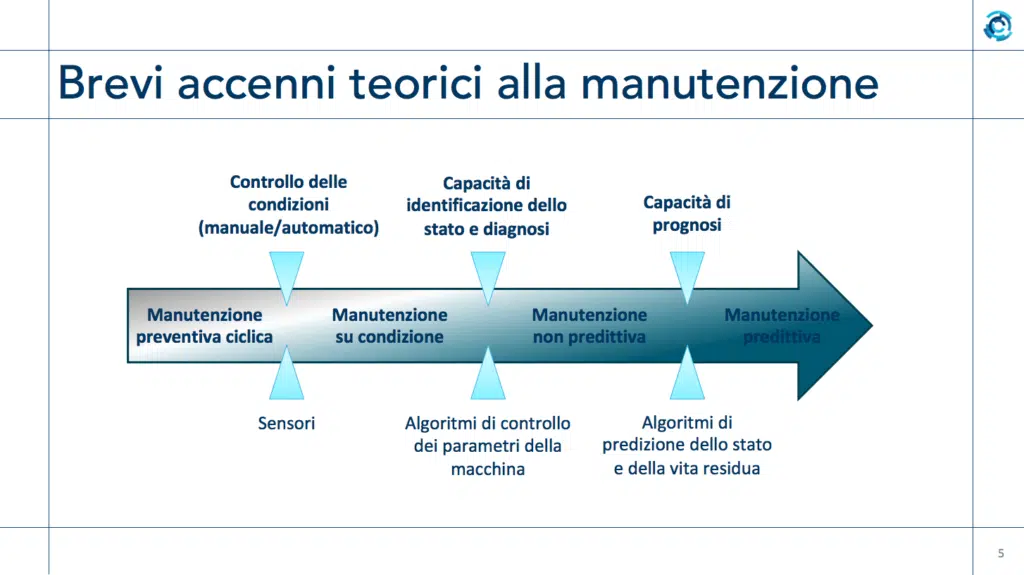
Perché la manutenzione predittiva
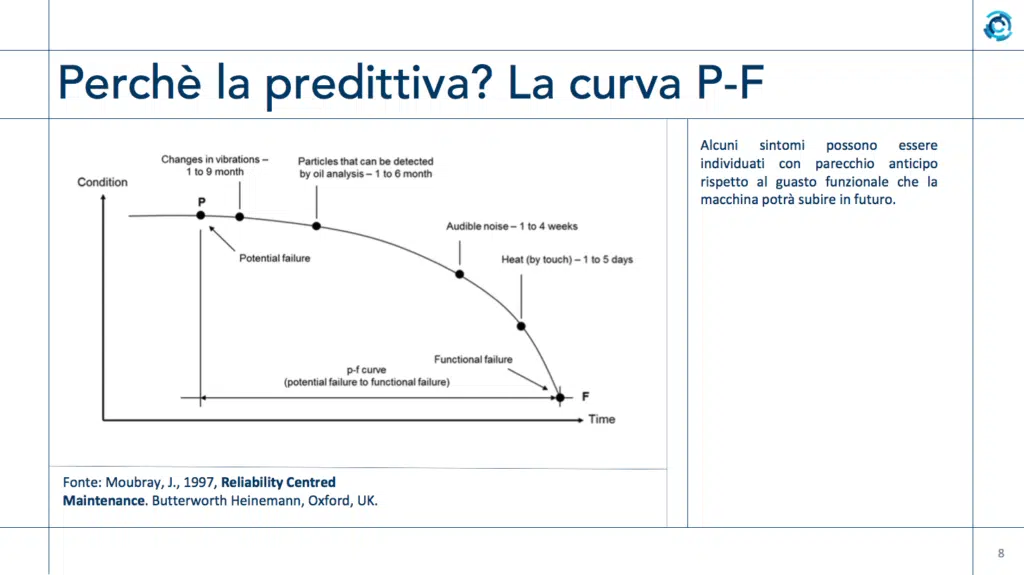
Sappiamo che qualsiasi macchinario degrada nel tempo. Per macchine molto semplici, che vengono usate in modo “stabile” (per esempio ventilatori, pompe), è abbastanza facile calcolare la curva che porta la macchina dalla stato di “possibile guasto a breve” a “guasto conclamato”. Si tratta di rilevare i sintomi: per esempio, per un cuscinetto a sfere sappiamo che un cambio delle vibrazioni indica una possibilità di guasto fra 1-9 mesi (a seconda del modello), e verrà seguita da altri sintomi quali particelle metalliche nell’olio di lubrificazione, variazione del rumore udibile, surriscaldamento. Tutti sintomi rilevabili tramite monitoraggio, storicamente compiuto dal manutentore che sente la vibrazione, vede l’olio sporco, ascolta il rumore, tocca la parte e la sente calda. Purtroppo, la maggior parte delle macchine non è né semplice, né usata in modo continuativo e senza variazioni, quindi calcolare questa curva (chiamata Curva P-F, da Potential Failure a Functional Failure) diventa una cosa complicata. Ma in ogni caso, l’abilità del mio manutentore (o la sofisticazione del mio algoritmo di analisi dei dati) mi consentirà di accorgermi in anticipo del possibile futuro guasto, e di intervenire prima che si verifichino problemi gravi, ma non tanto in anticipo da spendere in manutenzione più di quanto mi costerebbe arrivare al guasto. Sempre ché siamo in grado di stabilire la posizione temporale corretta del punto di guasto, naturalmente.
Per passare dallo schema qualitativo a uno schema più operativo, quantitativo, dobbiamo chiederci cosa ci serve in concreto per fare una manutenzione “avanzata”, per esempio su condizione. «Devo poter controllare un parametro particolarmente critico. Se dovessi ipotizzare punterei sulle vibrazioni – spiega Polenghi – e poi vorrei essere avvisato quando la macchina presenta qualche sintomo ed è prossima al guasto. Quindi il parametro verrebbe monitorato e quando supera un determinato livello il sistema deve generale un’allerta, che indica che la macchina può funzionare ma c’è qualcosa di diverso dalle condizioni ottimali. Poi vorrei che venisse generato un allarme quando la macchina funziona ma non sta rispettando gli standard richiesti. E quindi per esperienza sappiamo che sta per avvenire un guasto serio». Insomma, le due informazioni necessarie dal sistema definiscono la “zona verde”, in cui tutti i parametri monitorati sono entro i valori limite comunicati per esempio dal produttore della macchina, e i prodotti sono tutti validi senza scarti, e la “zona arancione”, definita fra il segnale di allerta e quello di allarme, dove le prestazioni non sono esattamente quelle attese e ci possono essere prodotti non conformi. Superati i parametri della soglia di allarme, si entra in zona rossa, con parametri fuori standard, prodotti che non rispettano gli standard qualitativi, e condizioni critiche del macchinario, ormai vicino al guasto.
Ma soprattutto, «è importante che a questi passaggi di soglia sia collegato un processo decisionale: ovvero, cosa faccio quando passo dalla zona verde alla zona arancione, o dall’arancione alla zona rossa? – ipotizza Polenghi – È importante perché la manutenzione su condizione dà molto supporto alla manutenzione, ma deve essere collegata al processo decisionale che le sta dietro, o al processo di funzionamento: se quando arrivo alla soglia non parte in automatico un ordine di lavoro, non avviso il responsabile, anche se ho l’algoritmo migliore al mondo esso non mi sta supportando nell’operatività generale». A fronte di investimenti in persone, hardware e software necessari per creare un sistema di monitoraggio, raccolta dati e analisi, potrò ottenere una serie di benefici che vanno dalla standardizzazione delle procedure, ai minori errori di registrazione, dalla riduzione dei tempi alla maggiore qualità delle informazioni. Quest’ultima voce in particolare è fondamentale, perché dalla qualità delle informazioni (in particolare, dalla corretta scelta dei parametri da monitorare) dipende il corretto funzionamento di tutto il modello.

Il modello di riferimento Osa-Cbm
Un modello di riferimento per l’implementazione di tecnologie di monitoraggio su condizione e diagnostica è quello descritto nel documento Iso 13374-1, “Condition monitoring and diagnostic of machines”. Fra i modelli disponibili, è l’unico che fornisce dei veri e propri “passi” da seguire per implementare il sistema. Esso è suddiviso infatti in 6 livelli o step, che partono dal Data Acquisition (da sensori o manuale) per procedere con Data Manipulation, State Detection, Health Assessment, Prognostic Assessment e Advisory Generation. La fase forse più critica, e che in genere richiede più tempo, è la Data Manipulation, nella quale bisogna rendere consistenti i dati acquisiti nello step 1. Possono esserci infatti letture errate o mancanti, dati inseriti manualmente e non corretti, irregolarità di vario tipo. Gli algoritmi devono essere in grado di “pulire” tutto. «Per darvi un’idea, in un progetto su una macchina utensile che è durato tre anni, circa due anni sono stati dedicati al Livello 2» puntualizza Polenghi. In pratica, fino al 70-80% del tempo viene investito nella “sanitizzazione” dei dati. Che è fondamentale, perché se sfruttassi i dati in arrivo dai sensori senza verificarli, potrei alla fine prendere decisioni sbagliate.
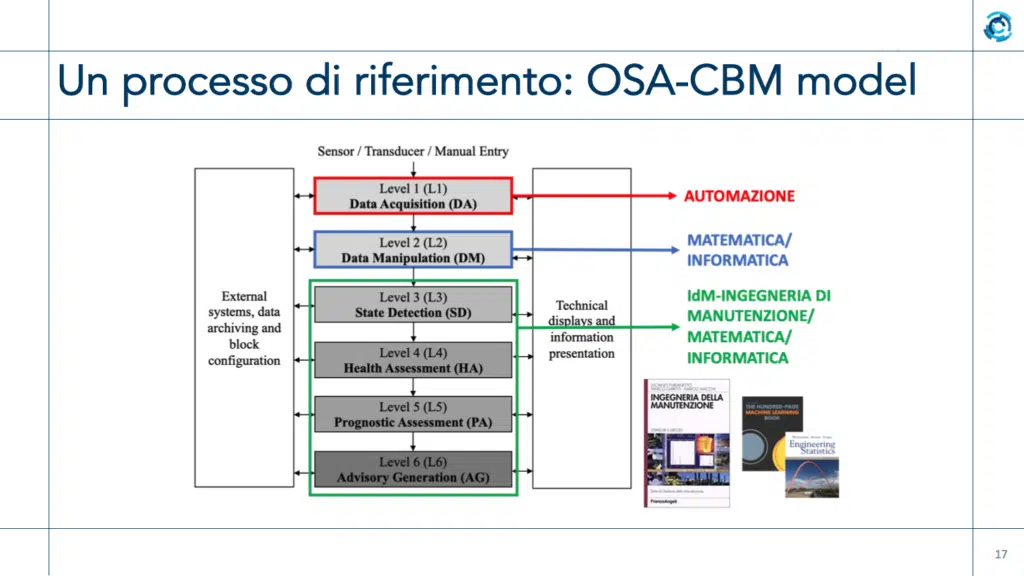
Una volta in possesso dei dati “puliti”, posso determinare lo stato della macchina (3) e se qualcosa non quadra cercare di determinare cosa non funziona (passo 4). In base ai risultati dello step il sistema può tentare una prognosi, ed è qui che entra in gioco l’idea di manutenzione predittiva, mentre fino allo step 4 stavamo ancora ragionando in termini di manutenzione su condizione. Infine, sempre in base ai risultati degli step 4 e 5, il sistema deve emettere un avviso (step 6) che potrebbe essere un verde (va tutto bene), arancio (qualcosa non quadra) o rosso (malfunzionamento e guasto imminente). Dal punto di vista dell’investimento necessario, quello in persone è preminente. Servono infatti esperti di automazione per il Livello 1 (la parte di sensoristica, trasduttori, data entry eccetera), ma anche matematici e informatici per il Livello 2 e successivi. Dal Livello 3 in su a prendere la guida delle operazioni devono essere gli ingegneri di manutenzione, sempre coadiuvati da informatici e matematici.
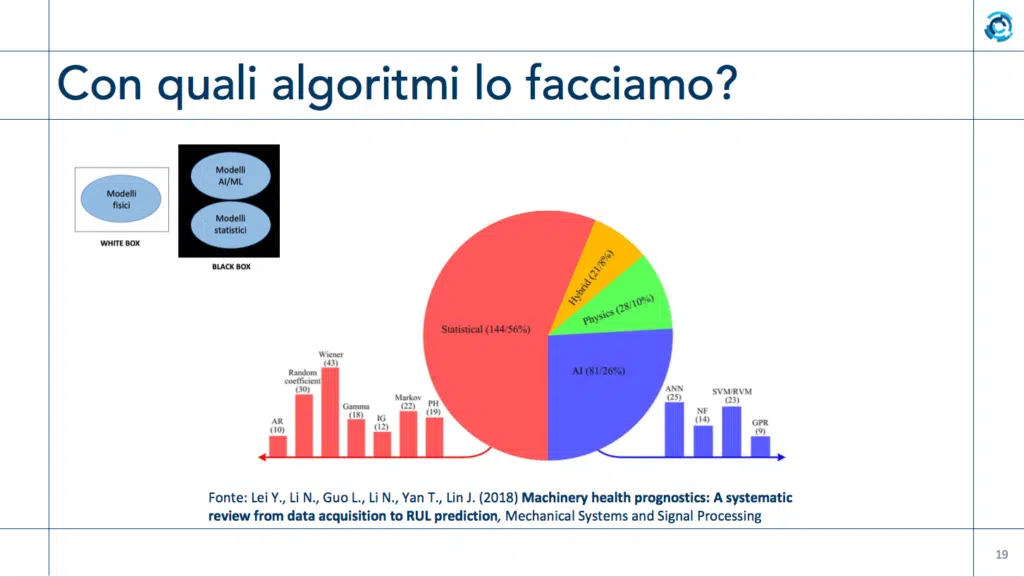
Dal punto di vista degli algoritmi utilizzabili per realizzare gli step del modello Iso 13374-1, secondo una rilevazione del 2018 la maggior parte dei sistemi impiega metodi di tipo statistico (56%), seguiti da quelli basati su Intelligenza Artificiale (26%). Altri sistemi impiegano algoritmi basati sulla fisica (scambio termico eccetera, circa 10%) o ibridi (8%). Il fatto che gli algoritmi statistici vengano preferiti a quelli più avanzati basati su IA è dovuto a vari fattori, ma il principale sembra essere che l’IA per sua natura tende a essere una sorta di “black box”: quando fa una previsione, non spiega il perché. Magari può avvisare che “la parte X si romperà fra 4 ore”, ma non dice quale dato le ha permesso di fare questa previsione, in base a quale criterio ritiene ci sarà il guasto, come ha determinato il lasso di tempo. E in ambito industriale non possiamo accettare a scatola chiusa una previsione della quale non possiamo replicare il ragionamento per convalidarlo, cosa fattibilissima con gli algoritmi statistici, ma ancora impossibile con le reti neurali (o IA che dir si voglia).
L’importanza dei Big Data

Finora abbiamo parlato essenzialmente del dato di macchina, legandolo soprattutto alle operazioni di manutenzione. Ma sappiamo che in un’azienda non ci sono solo i dati che arrivano da bordo macchina: ci sono anche tutti quelli che sono prodotti da processi aziendali. Quindi questi dati mi servono non solo per sapere come vanno i miei macchinari, ma anche come va la mia azienda al suo interno, e come si pone rispetto al mondo esterno. L’enorme quantità di dati di varia provenienza, sensoristica, data entry, processi aziendali eccetera viene definita tipicamente “Big Data“. Si tratta di un concetto che non ha una vera e propria definizione ufficiale o standardizzata, ma spesso lo si descrive con le “5 V“: Volume, Variety, Velocity, Veracity e Value. Parliamo di Big Data quando siamo in presenza di grandi masse di dati da multiple sorgenti (macchinari, contabilità, Erp, Social Media, Supply chain…), di tipologie diverse (strutturati, semi-strutturati e non strutturati), che vengono create rapidamente, che vengono controllati per essere sicuri della loro correttezza e che rivestono un valore per il business. Da questa descrizione appare chiaro che quando parliamo di dati in ambito Industria 4.0 parliamo, quasi fatalmente, di Big Data. Soprattutto quando cominciamo a integrare il dato di macchina con dati di altra provenienza (altre macchine, linee complete, software in ambito business e via discorrendo). Il concetto di Big Data “trascina” poi con sé una serie di altri paradigmi: il cloud per esempio, visto come soluzione preferenziale per memorizzare ed elaborare i dati; o l’IA, utile per l‘analisi previsionale eccetera. Inoltre, i Big Data portano in azienda una serie di sfide: come acquisisco i dati? Dove li memorizzo? Che dati possiedo? Come li analizzo? Quanto mi costano?
Il dove li memorizzo, per esempio, non è per nulla banale. La soluzione preferita oggi è il cloud, perché garantisce maggiore sicurezza dei dati sia da intrusioni esterne, sia da disastri (incendio dell’azienda per esempio, o crollo per terremoto). tuttavia, le quantità di dati in gioco sono spesso molto elevate, e per alcune elaborazioni diventano importanti anche i tempi di latenza (per esempio individuare anomalie in macchine con tempo di ciclo di pochi millisecondi). Così si deve bilanciare la gestione fra dati che possono essere mandati in cloud per l’elaborazione e dati che vanno elaborati in parte on premise per evitare problemi di latenza, e inviati successivamente al cloud per altri usi. Questo sta facendo emergere nuove forme di organizzazione dei dati, come il Fog Computing. «Il Fog Computing cerca di creare una specie di continuum fra ciò che ho in locale e ciò che ho in cloud – spiega Pierluigi Plebani – Non sono io a decidere dove mettere i dati, è il sistema che determina la collocazione migliore, in modo da consentire la maggiore efficienza nell’utilizzo dei dati stessi». La necessità di bilanciare fra dati in cloud e on prem deriva ovviamente dal fatto che sul cloud avrò maggiori risorse di storage e minori costi, ma appunto potrei avere una latenza inaccettabile per certi compiti, i quali richiedono elaborazione in locale che è, appunto, molto più costosa.

Dal data warehouse al data lake
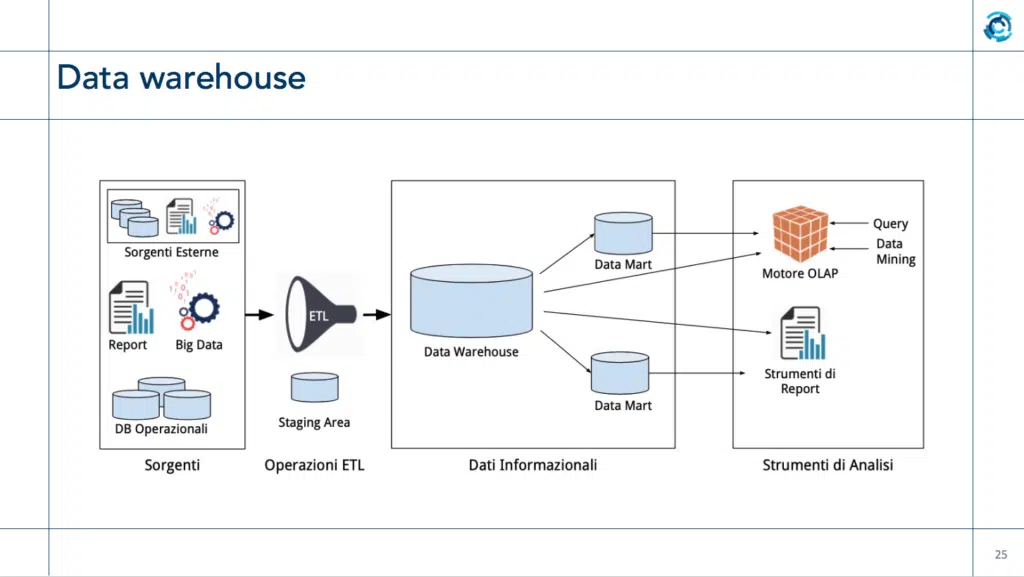
«Dobbiamo sempre poter distinguere i dati della mia organizzazione da come posso analizzare i dati stessi – spiega Plebani – e fra i primi strumenti che davano la possibilità di condurre analisi sui dati c’è stato il data warehouse, che lavorava principalmente su dati strutturati». Con questo strumento, quando i dirigenti avevano bisogno di eseguire un’analisi, interveniva un esperto di data base che, in base alle richieste dell’utente, creava i “Data Mart“, in pratica definiva un processo di estrazione (Etl), una fase di trasformazione per rendere omogenea la presentazione, e infine una fase di loading, nella quale questi dati venivano inseriti in un modello omogeneo, il data mart (in gergo “il cubo”). Qui i dati erano organizzati in modo adatto a rispondere alla query richiesta, per esempio tramite una dashboard. «Il problema di questo sistema è che è poco flessibile – continua Plebani – sia perché tratta soprattutto dati strutturati, sia perché se cambio idea su come devono essere fatti i data mart, devo rimettere mano a tutto il sistema». Inoltre, questo sistema soffre il problema del “one size fits all”, ovvero uno strumento deve andare bene per tutto.
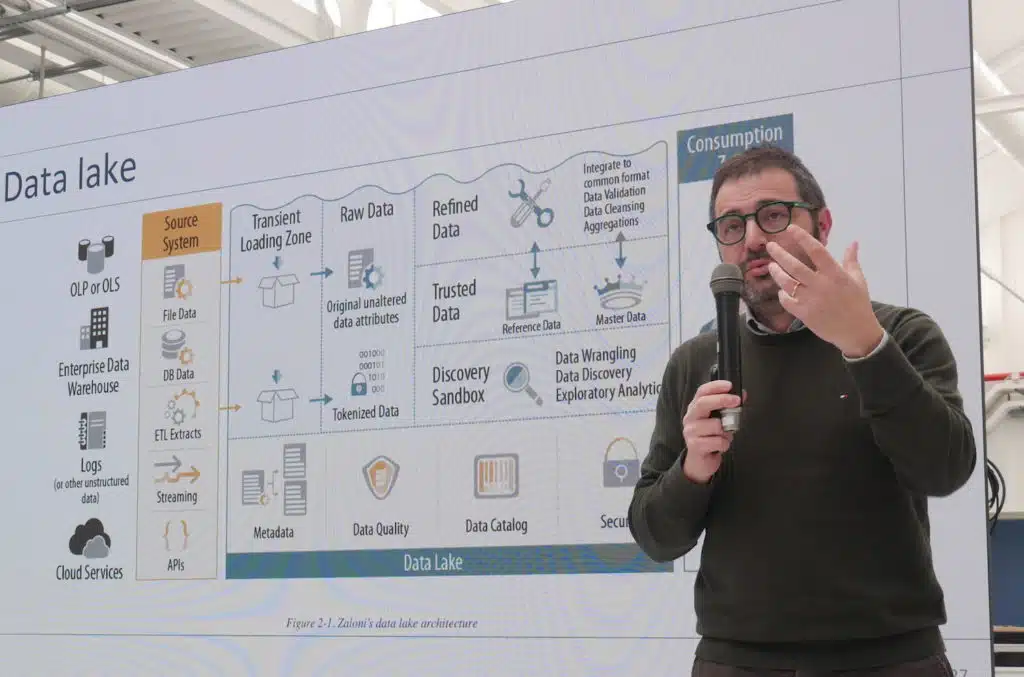
Principalmente per questi motivi, si è passati a utilizzare un modello più sofisticato, quello del Data Lake. Uno strumento più flessibile, anche perché ci sono varie possibilità di implementazione. In un Data Lake fondamentalmente «ho tutti i dati che voglio memorizzare, e di questi dati faccio un’estrazione e una trasformazione minima, soprattutto se confrontata con la fase di trasformazione dei data warehouse che era molto complicata – dice Plebani – Di fatto, prendo i dati, faccio il minimo indispensabile per garantirne la qualità, e li memorizzo nel loro formato iniziale. Quindi non forzo il sistema a snaturare il formato iniziale per portarlo a una forma comune. Infine ti obbligo a inserire nel data catalog un entry che informi del fatto che hai inserito dei dati, e indica quali sono. Uno sviluppatore che voglia fare un’analisi dovrà solo cercare il dato più adeguato, usare lo strumento più adatto al tipo di dato e all’obiettivo dell’analisi, e potrà eseguire l’analisi ottenendo la segmentazione richiesta».
Le demo
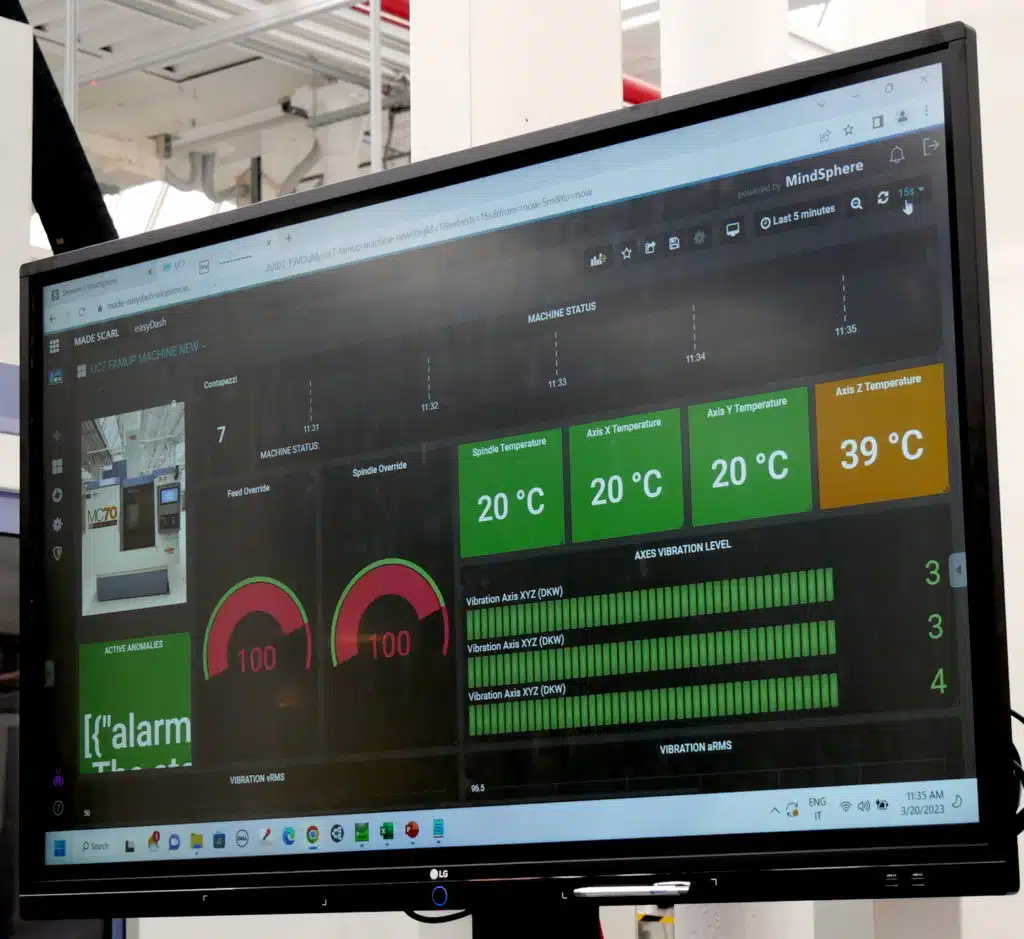
Sfruttando i dimostratori tecnologici del Made, in particolare per l’area 5 e 6, è stato possibile mostrare alcune demo di sistemi di raccolta, gestione, analisi dei dati in ambito macchina, fabbrica e impresa. In particolare, le demo erano basate sull’architettura data lake del Made, che permette di gestire la quantità di dati prodotta dalle macchine usate nelle dimostrazioni e le relative analisi. Fra le tecnologie dimostrate, citiamo il retrofitting di una macchina utensile per consentirne il monitoraggio tramite raccolta di dati digitali; l’utilizzo dei dati raccolti per sviluppare un sistema di gestione della manutenzione su condizione; la gestione dei Big Data tramite strumenti software in grado di governare in modo efficace ed efficiente enormi quantità di dati in arrivo dalle macchine; e infine la gestione di dati eterogenei, provenienti sia dalle macchine che dal comparto amministrativo di un’azienda, tramite un Data Lake che consente di realizzare analisi sinergiche.