


La GenAi, Intelligenza Artificiale Generativa, è qui per restare. Ne sono più che convinti gli uomini di Amazon Web Services (Aws), uno dei maggiori fornitori di servizi di cloud computing a livello mondiale, con un fatturato 2022 di circa 80 miliardi di dollari. Durante il recente webinar Aws re:Cap, che riprendeva gli annunci avvenuti poche settimane fa all’evento aziendale Aws re:Invent di Las Vegas, è apparso chiaro che la GenAi avrà un posto centrale nei piani di sviluppo per i prossimi mesi, tanto da essere presente praticamente in tutti gli annunci, nella forma che sempre più spesso viene indicata come Business Ai, ovvero, l’intelligenza artificiale generativa per le aziende. Nei piani di Aws, le onnipresenti tecnologie Ai sostanzialmente seguono due filoni di impiego. Da una parte, Aws si sta attrezzando per consentire ai suoi clienti di poter attivare applicazioni business basate su Ai con prestazioni di prim’ordine sia nella fase di addestramento dei modelli, sia nella fase operativa vera e propria. Questo sta comportando l’installazione nei data center di Amazon Web Services di nuovi hardware specifici per l’Ai, come per esempio i processori Trainium2 ottimizzati per il Machine Learning, che andranno ad affiancare i processori general purpose Graviton4, sviluppati da Aws con tecnologia Arm, e le tradizionali macchine Intel/Amd.
Ma non solo. Gli aggiornamenti in chiave Ai riguardano soprattutto il software. Per esempio, i vari database disponibili sono stati messi in grado di gestire ricerche vettoriali, un prerequisito fondamentale per le query di Ai. Il secondo filone di implementazione dell’Ai riguarda invece l’uso delle tecnologie di Intelligenza Artificiale da parte dei clienti Aws per rendere più semplice, potente e completa l’interazione con i servizi cloud dell’hyperscaler. L’obiettivo, in pratica, è semplificare la vita al cliente, consentendogli per esempio di usare l’Ai per dimensionare e attivare servizi e applicazioni, per collegare fra loro differenti task senza dover disporre di programmatori esperti per scrivere il necessario codice (che verrà generato dall’Ai), per automatizzare i processi e per avere una visione più dettagliata dell’andamento dei propri servizi Aws – in questa direzione va per esempio la nuova console unificata per Billing & Cost Management.



La maggior parte di questi compiti viene svolta interagendo con Aws Q, un servizio che agisce a tutti gli effetti come un consulente esperto nei servizi Amazon Web Services. Il cliente interagisce con Q principalmente tramite un’interfaccia utente in linguaggio naturale, risultando quindi facilmente approcciabile anche da personale It non particolarmente “skillato” sul funzionamento interno dei vari servizi. Amazon Q può interagire anche con SageMaker, il servizio gestito che consente di creare, addestrare e implementare i propri modelli di machine learning, con CodeWhisperer, per la generazione di codice, e in generale con la maggior parte dei servizi di Aws. A sua volta, Q sfrutta per il suo funzionamento Bedrock, una piattaforma basata su Foundation Model precostituiti, specializzata nella creazione di applicazioni Ai sul cloud Aws.
Due parole sulla GenAi
La storia dell’informatica è piena di tecnologie apparentemente geniali che si sono rapidamente sgonfiate (Metaverso, social network voice-based, eccetera). Ma questo non è il caso della Gen Ai, o Intelligenza Artificiale Generativa. Essa si candida anzi ad essere la tecnologia di più rapida adozione nella storia del digitale, visto che ChatGTP ha raggiunto il milione di utenti in 5 giorni (contro i due mesi e mezzo di Instagram e i 3,5 anni di Netflix, per fare un paragone) e i 100 milioni in due mesi. E il motivo è chiaro: per la prima volta, una tecnologia informatica fa realmente risparmiare tempo e denaro a chi la usa, consentendo di portare a termine svariati compiti in tempi nettamente più brevi, e con personale meno “skillato”.
La velocità con cui le soluzioni GenAi stanno prendendo piede è tale che le società di ricerche di mercato stanno rivedendo al rialzo le loro stime mese dopo mese. Fra le stime più recenti, citiamo quelle di Idc, secondo la quale la spesa delle aziende per la GenAi è stata pari a 16 miliardi di dollari nel 2023 e salirà a 143 miliardi nel 2027, con un Cagr del 73,3%. In termini percentuali, l’Ai salirà dal 9% al 28% degli investimenti IT delle aziende. Fortune Business Insights è ancora più ottimista, e stima il mercato 2023 a quasi 44 miliardi di dollari, con previsioni per il 2030 a un soffio dai 668 miliardi (Cagr 47,5%), con i settori del manifatturiero, dell’healthcare e dell’IT a dividersi grosso modo in parti uguali i due terzi della somma. Stime ancora superiori le danno Bloomberg Intelligence, che parla di un mercato 2032 da 1.300 miliardi, e Market Research Future, che si sbilancia su un totale di quasi 1.590 miliardi di dollari entro il 2030. I numeri ovviamente cambiano anche in base a cosa gli analisti includono nell’indagine, ma non c’è dubbio che l’impatto di questa tecnologia nei prossimi 10 anni sarà davvero pervasivo, con effetti prima di tutto sul settore IT (e sui suoi livelli occupazionali) e a seguire su quelli del medicale, del customer care e via discorrendo.

Aws, la nuova infrastruttura per implementare servizi basati su Ai Generativa
Per un hyperscaler, consentire ai clienti di implementare servizi basati su Ai richiede un lavoro preparatorio non indifferente. Nel caso di Aws, questo lavoro ha riguardato sia l’hardware, sia il software dell’infrastruttura. Sul fronte hardware, c’è stata l’introduzione di nuovi processori sviluppati internamente che garantiscono maggiore potenza di calcolo (Graviton4 per il compute generico e Trainium2 dedicati specificamente al machine learning, in particolare all’addestramento dei Foundation Model e dei Large Language Model con trilioni di parametri. Si tratta della seconda generazione dei chip per intelligenza artificiale progettati negli Aws Annapurna Labs, e le specifiche sono notevoli: le performance sono quadruple rispetto alla prima generazione, le performance per Watt sono raddoppiate e la memoria disponibile triplicata (siamo a 96 Gb). Con il dispiegamento in forze dei nuovi chip, Aws conta di offrire ai suoi clienti fino a 65 ExaFlops sui carichi di lavoro Ai, grazie alla capacità di scalare su un massimo di 100.000 chip. Tradotto in concreto, Aws promette di ridurre il tempo di addestramento di Llm con 300 miliardi di parametri da alcuni mesi a qualche settimana.
Il software e i servizi

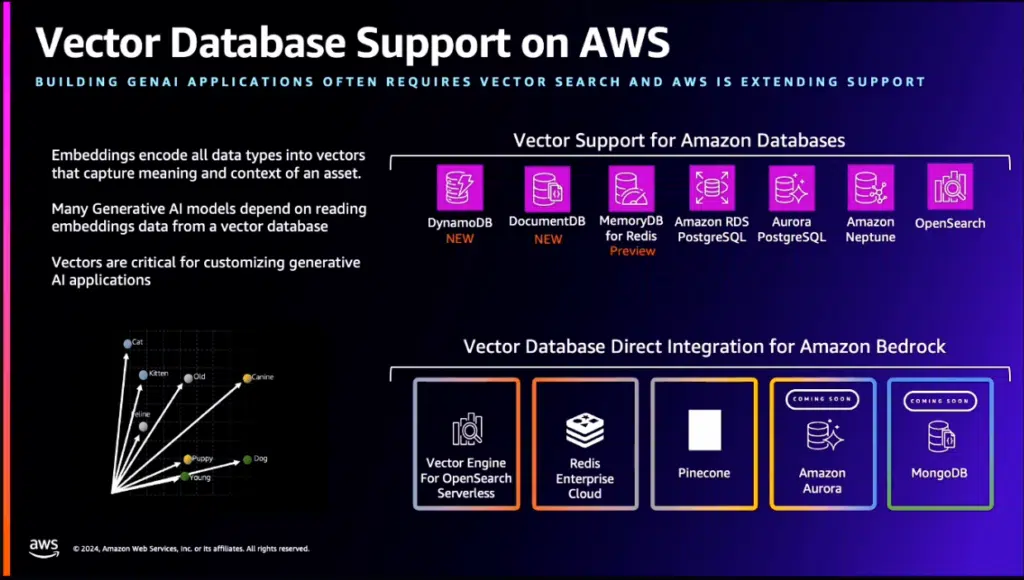
Anche la migliore piattaforma hardware può fare ben poco se non supportata da una adeguata dotazione software, che ne permetta un uso efficiente. E in vista dell’arrivo di carichi di lavoro sempre più imprevedibili nel loro comportamento, come sono quelli di Ai, Aws ha per prima cosa migliorato le caratteristiche di scalabilità delle istanze ad alto volume. Nella nuova implementazione del Lambda Scaling, la velocità di scaling è 12 volte maggiore di prima, con un massimo di 1.000 esecuzioni concorrenti in più ogni 10 secondi, naturalmente con un limite massimo stabilito dall’account del cliente. Anche lo scale-out dell’Aurora Limitless Database è stato potenziato, e ora può scalare automaticamente a milioni di transazioni al secondo, gestendo basi dati classe Petabyte. Disporre di data base adeguati è un altro punto fondamentale per aprire la strada all’Ai. Adeguati, in questo caso, vuol dire capaci di eseguire ricerche semantiche, o vettoriali che dir si voglia.
Con gli ultimi annunci, Aws ha messo a disposizione il supporto vettoriale su diversi database (DynamoDB, Aurora, Neptune, OpenSearch…) e supporta l’integrazione diretta dei database vettoriali (Aurora, MongoDB, Pinecone, Vector Engine for OpenSearch, Redis) nella piattaforma Bedrock (ne parliamo più avanti). Anche Amazon RedShift è stato integrato con gli altri database operazionali, con i servizi di machine learning e le applicazioni di business intelligence, fra l’altro senza la necessità di creare complesse pipeline Etl (Extract, Transform & Load). Infine, sono state ridefinite le Storage Class, per ridurre i costi di immagazzinamento dati e per fornire prestazioni in linea con le necessità delle applicazioni di Ai. Ora c’è una classe Archive per i dati da conservare ma cui raramente si accede, una classe Efs Infrequent Access e la classe EFS Standard. Questa nuova suddivisione garantisce un costo per lo storage di dati Ai ridotto del 36%, e un costo per la classe Archive che è la metà di quello dei dati Ai.
Aws Q, per interagire con i servizi Aws in linguaggio naturale
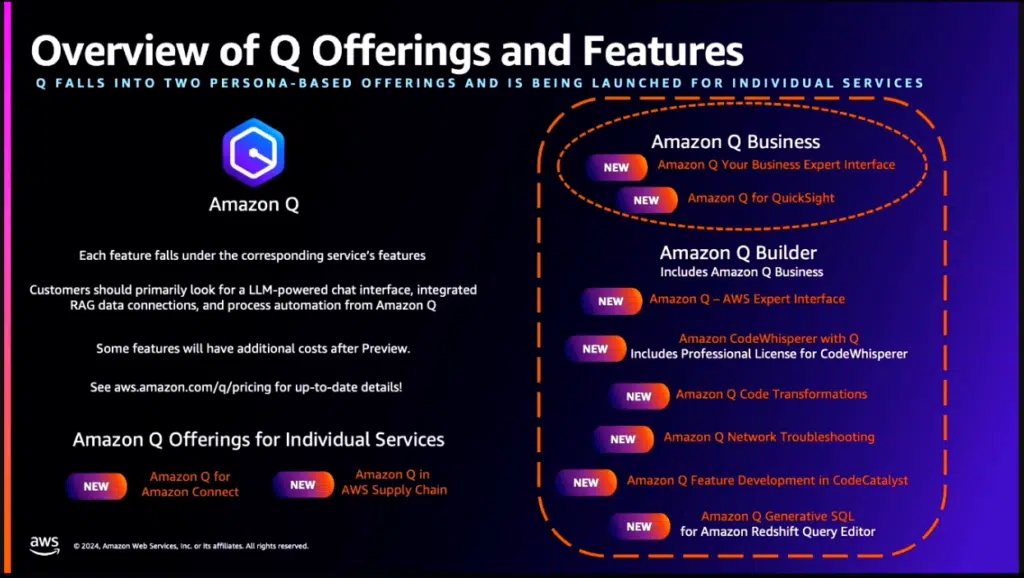
Finora abbiamo parlato di quello che accade dietro le quinte, ma gli annunci più interessanti riguardano ovviamente gli strumenti con i quali il cliente può interagire direttamente, e le piattaforme che ne consentono il funzionamento. La novità più importante è probabilmente Aws Q. «Amazon Q è un assistant basato su Intelligenza Artificiale Generativa – ha spiegato Antonio D’Ortenzio, solution architect manager di Aws – creato per scopi di business e personalizzabile rispetto alle specificità della realtà del cliente. Q mette a disposizione le sue funzionalità verso un ampio spettro di tool e servizi Aws ed è estendibile alla fonti di dati, ai sistemi e alle informazioni del cliente mediante oltre 40 connettori già disponibili». In pratica, questo assistant si configura come un servizio per l’interazione con i servizi Aws tramite un’interfaccia in linguaggio naturale, e grazie alla sua personalizzabilità fornisce risposte basate sulle basi di conoscenza del cliente; tra l’altro, Q riconosce le permission dell’utente che lo sta interrogando, e di conseguenza mostra solo risposte contenenti informazioni cui quell’utente è autorizzato ad accedere. Un caso d’uso tipico è una sessione di domande e risposte in cui Q utilizza dati dalle fonti aziendali più eterogenee, dalle wiki interne ai siti Sharepoint del cliente, ai dati Salesforce e così via. Si può usare anche per riassumere documenti, o per accelerare la creazione di contenuti. Ancora, consente di interagire in linguaggio naturale con QuickSight, l’applicazione Aws per la creazione di report visuali.
Fin qui abbiamo parlato di quello che viene indicato da Aws come “Q for Business”, ma c’è anche una componente ancora più sofisticata che risponde al nome di “Q for Builder”. Questa parte è stata specificatamente creata per sviluppatori e professionisti IT, ed è una sorta di “sistema esperto” che incorpora 17 anni di esperienza sui sistemi Aws. «Q for Builder consente per esempio di esplorare le nuove capacità di Aws, di imparare tecnologie che non conoscete o addirittura di architettare soluzioni – spiega D’Ortenzio – potete fare domande quali “Come posso costruire un’applicazione Web su Aws?” oppure “Quale istanza EC2 mi consigli di usare per questo particolare workload?”. Può essere anche usato per risolvere problemi: se vi trovare un errore in console, premete il pulsante di troubleshooting di Q e vi verranno forniti suggerimenti per risolverlo».
La piattaforma Bedrock
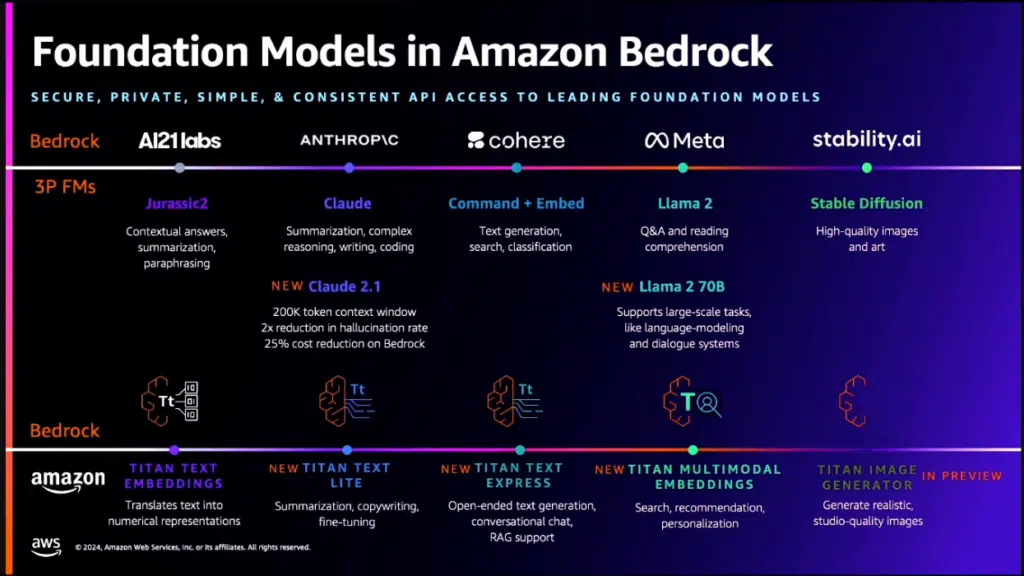
Amazon Q Builder si interfaccia poi con CodeWhisperer, e può quindi generare codice, e con altri servizi come il Network TroubleShooting, il Query Editor generativo per RedShift e altri ancora. L’integrazione con tanti servizi è resa possibile dal fatto che Q, esattamente come altri servizi e applicazioni, si basa su una sottostante piattaforma che fa da base a tutta l’architettura di GenAi di Amazon Web Services, chiamata Bedrock. È questa piattaforma a mettere a disposizione di tutto lo stack i vari Foundation Model, sia nativi di Amazon (la famiglia Titan), sia di terze parti. Tra questi ultimi citiamo il modello Claude di Anthropics, Llama 2 di Meta, Stable Diffusion di Stability.ai. Il tutto tramite semplici chiamate Api. È anche possibile personalizzare i modelli usati, sia tramite “fine tuning”, sia in altri casi tramite un processo di pre-training, ovvero addestrandoli con dati aggiuntivi riguardanti per esempio il settore nel quale opera il cliente.
Al momento, questa seconda possibilità è disponibile per i modelli Aws. L’azienda tiene a sottolineare comunque che nessuno dei dati in ingresso o in uscita di Bedrock con un determinato cliente verrà usato per addestrare ulteriormente i modelli originali, e questo a garanzia della privacy del cliente. Quello della privacy dei dati usati per il training è in effetti un argomento piuttosto scabroso nel mondo dell’Ai, e Aws ha operato saggiamente tenendo in considerazione le problematiche relative alla privacy e alla sicurezza delle informazioni fin dalle prime fasi del progetto dell’infrastruttura. In questo modo, diventa più semplice implementare nuove funzioni relative alla riservatezza sia nel sistema, sia nei servizi e nelle applicazioni basati sulla piattaforma. Tanto che una delle novità annunciate è proprio Guardrails for Bedrock, un “sistema di sicurezza” che consente di implementare policy per realizzare la cosiddetta “Ai responsabile”.
Sagemaker
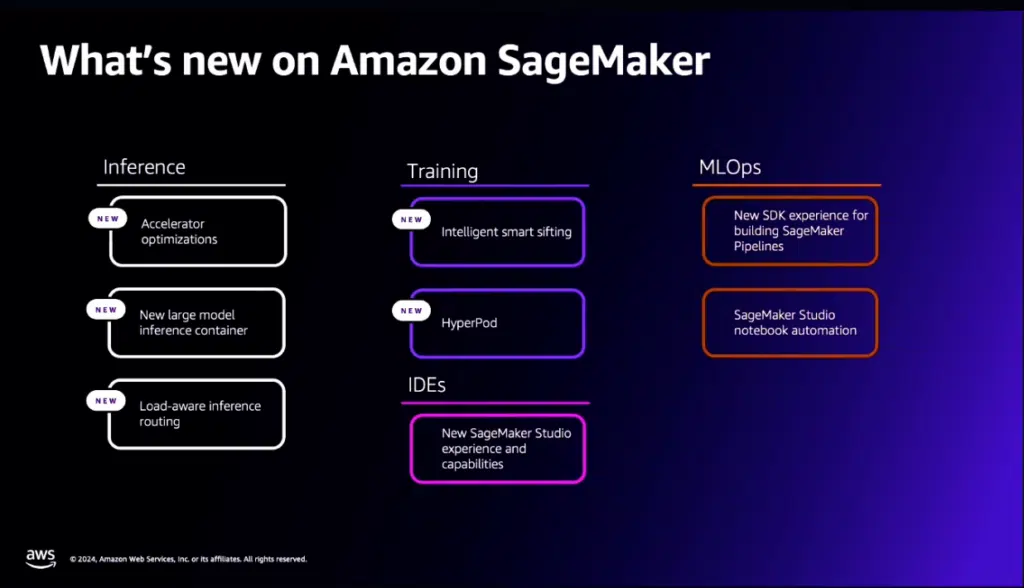
Su Bedrock è anche basato il servizio Sagemaker, che consente di creare, addestrare e implementare modelli di machine learning. Con gli ultimi annunci, SageMaker è ora dotato di nuove caratteristiche di ottimizzazione per gli acceleratori, di un nuovo container per l’inferenza su large model, e di capacità di fare routing inferenziale in base al carico. Ma soprattutto, è stata aggiunta la capacità di fare Intelligent Smart Sifting: in pratica, il sistema è in grado di “capire” quali sono i dati più significativi da cui imparare, e quali sono quelli meno adatti all’uso in fase di addestramento. «Poiché questi dati hanno un minore impatto sull’apprendimento del modello, essi vengono scartati in automatico. Questo permette di ridurre i tempi di addestramento del modello, e i relativi costi, fino al 35%» ha spiegato Stefano Sandrini, solution architect di Aws. Un’altra nuova caratteristica in grado di ridurre tempi e costi è chiamata HyperPod. «HyperPod semplifica il training distribuito, dividendo i task di training in un cluster ed elaborandoli in parallelo – prosegue Sandrini – il cluster è resiliente, self-healing e consente di mettere in pausa, ispezionare, ottimizzare il training in modo interattivo, con un risparmio di tempo che arriva fino al 40% nei modelli di base».
Tutto disponibile, o quasi

La maggior parte delle novità di cui abbiamo parlato in questo articolo, viste durante il webinar re:Cap, sono state presentate in dettaglio da Aws all’evento Re:Invent, tenutosi recentemente a Las Vegas. Tuttavia, non tutte le novità sono già disponibili commercialmente: alcune sono in fase di Preview, sorta di beta pubblica, e soprattutto non tutte le novità saranno rese disponibili in contemporanea su tutte le “Region” di Aws, per cui è possibile che, in base alla Region di appartenenza del cliente, non si possano ancora sfruttare alcuni dei nuovi servizi. Una buona occasione per fare il punto della situazione sarà il prossimo Aws Summit di Milano, che si terrà il 23 maggio 2024 presso l’Allianz MiCo – Milano Convention Center.









