


Prossima fermata: intelligenza artificiale spiegabile, in grado non solo di prendere decisioni, ma anche di giustificarle all’intelligenza umana. Ma, per adesso, la grande sfida delle imprese italiane ed europee è quella di implementare l’AI al momento disponibile, all’interno dei processi produttivi, sfruttandone le grandi potenzialità che offre nell’ambito supply chain. Il numero di aziende che hanno già adottato queste soluzioni è ancora limitato. I casi di applicazione reale, però, dimostrano che i benefici sono tangibili.
Accertare 130 anomalie in una pipeline petrolifera che altrimenti sarebbero rimaste non identificate fa la differenza, da un punto di vista industriale, economico e anche reputazionale. Così come riuscire a prevedere le vendite di un’azienda manifatturiera come mai prima d’ora. Al centro dei processi, però, resteranno sempre le persone. Ecco quello che hanno raccontato Francesco Falcolini, Business analytics consultant di Quin, e Roberto Verdelli, Artificial intelligence & advanced analytics practice manager di Techedge, nell’ambito di un evento targato Made – Competence Center Industria 4.0, moderato da Giovanni Miragliotta, docente del Politecnico di Milano e Co-direttore dell’Osservatorio Industria 4.0.



La miniera d’oro del dato e le fasi di estrazione del valore

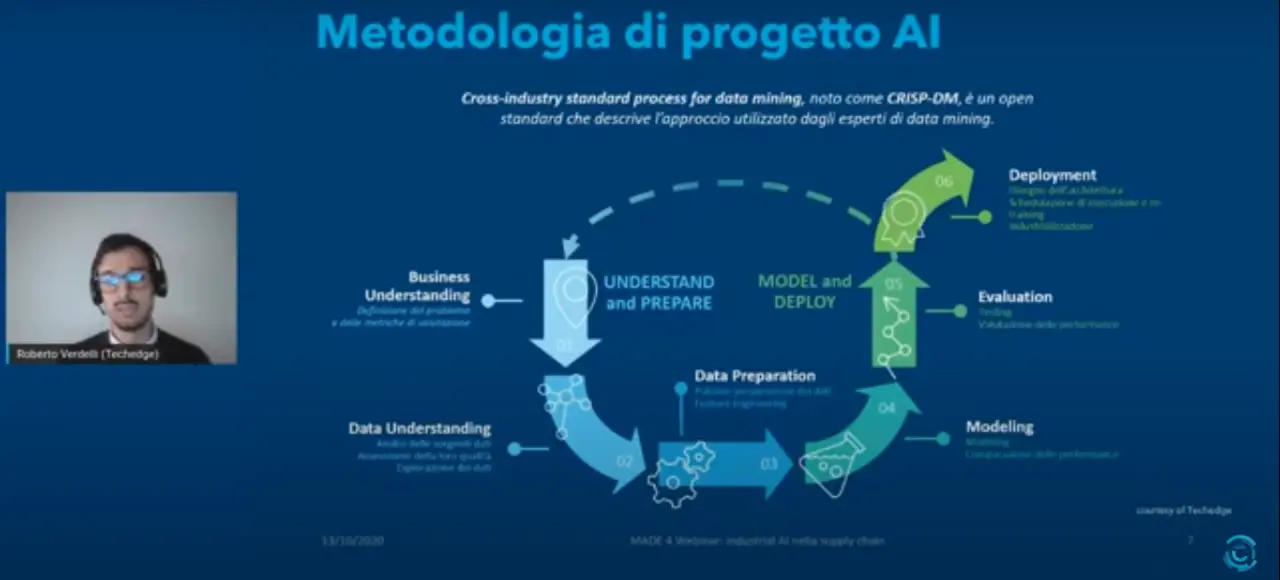
«I progetti AI sono un po’ diversi da quei progetti che si siamo abituati a vedere tradizionalmente nel mondo IT. Sono diversi perché vedono al centro il dato, la nostra miniera d’oro dalla quale saremo chiamati ad estrarre valore» ha chiarito subito Verdelli. Uno degli approcci più noti allo stato dell’arte per affrontare questo tipo di attività è chiamato CRISP-DM: Cross-Industry Standard Process for Data Mining, un approccio che per iterazioni successive va a migliorare le performance di quanto realizzato, fino a raggiungere una soglia obiettivo, ovvero la quantità di valore che si voleva creare nel momento in cui si è avviata l’attività.
Si comprende subito la particolare tensione operativa di questo tipo progetti, che generalmente partono da una fase di business understanding, per comprendere a fondo il problema, le metriche da utilizzare per la valutazione e l’efficacia del sistema che andremo a realizzare, e che dovrà risolvere il problema. C’è poi una parte cruciale di data understanding, in cui gli esperti di AI e gli esperti di business si siedono allo stesso tavolo per comprendere a fondo il dato. Si procede poi ad una fase di data preparation, in cui i dati vengono non solo preparati e puliti, ma anche ingegnerizzati per permettere ai modelli di estrarre il massimo dell’informazione utile ai loro scopi. Da qui parte il ciclo iterativo, con una serie di insights che reinseriti nel ciclo permettono migliorare le fasi precedenti e andare ad ottenere modelli più precisi.
Le declinazioni AI nell’universo supply chain
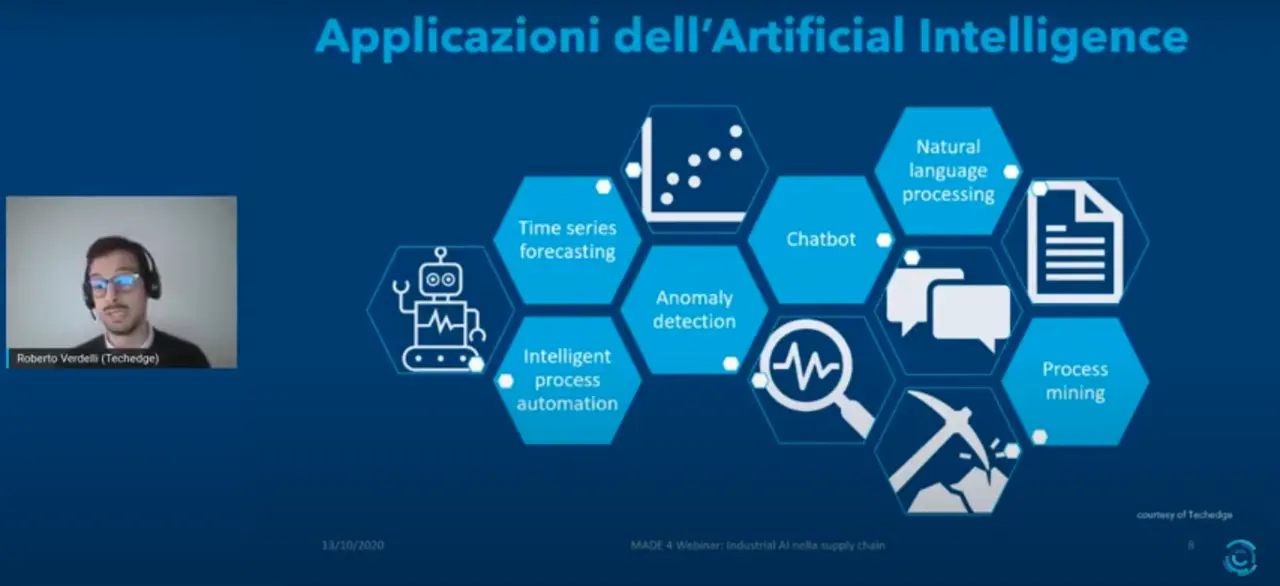
Le declinazioni delle metodologie AI all’interno della supply chain sono tantissime. «Pensiamo ad esempio al mondo del time series forecasting applicato alla domanda, cioè la previsione della domanda, con l’obiettivo di migliorare pianificazione delle produzioni, approvvigionamenti e gestione dei magazzini – dice Verdelli – La maggior parte dei casi fa riferimento ad applicazioni per la selezione dei fornitori, oppure per prevedere il prezzo di materie prime, per determinare le priorità di produzione nell’ambito della gestione del magazzino, o diretti all’ottimizzazione delle scorte in sicurezza e dei punti di riordino dei prodotti. Nell’ambito del production management c’è un mondo: stimare lead time e manutenzione predittiva, prevedere la qualità dei prodotti sulla base dei dati acquisiti di produzione, rilevare i rischi, stimare le caratteristiche di un bene per trovare il modo ottimale di trasportarli nell’ambito del transportation management» aggiunge Falcolini. A queste applicazioni di frontiera vanno aggiunte anche quelle commodity, cioè quelle che permettono di affrontare in maniera più efficiente ed efficace compiti apparentemente banali. È il caso dei chatbot, in grado di gestire le interazioni di primo livello con i clienti, raccogliendo inoltre preziosi feedback. Oppure la branca del natural language processing spesso utilizzata per la digitalizzazione di documenti.
Implementazione ancora limitata nelle più grandi aziende europee

Secondo una ricerca condotta nel 2019 dall’Università di Warwick, l’applicazione dell’intelligenza artificiale nell’industria europea è ancora limitata. L’indagine ha coinvolto 180 tra le maggiori aziende manifatturiere in Europa, e si è basata su un modello a quattro livelli. Nel primo livello l’obiettivo è di avere visibilità di tutta la catena logistica end-to-end, con analytics di base, un sales operation planning gestito in modo manuale, e silos e informativi all’interno dell’organizzazione. Il secondo livello è predittivo, con strumenti ad hoc per il sales operation planning, insieme ad altri sistemi informativi più evoluti. Il terzo livello è invece prescrittivo, con una pianificazione aziendale integrata, un piano unico che collega perfettamente i piani strategici con i piani di vendita, i piani operativi, i piani finanziari, bilanciando allo stesso tempo i vincoli a pratici con la disponibilità di risorse e gli obiettivi dell’azienda.
In questo caso siamo davanti a una pianificazione end-to-end dinamica, e viene utilizzato il machine learning nel supply chain management. L’ultimo livello è quello più evoluto: non c’è soltanto l’aspetto prescrittivo, bensì l’automazione della decisione. Ebbene, la ricerca mostra che solo il 13% delle 180 aziende manifatture più grandi in Europa ha raggiunto la maturità del terzo livello. C’è dunque ancora molta strada da fare, e le ricerche in questo campo concordano: nei prossimi anni ci sarà una crescita enorme dell’adozione dell’intelligenza artificiale, tre volte maggiore rispetto ad altre tecnologie su cui si è già investito molto negli scorsi anni, come ad esempio la sensoristica, l’IoT, o la robotica.

Anomaly detection, l’applicazione dell’AI in una supply chain petrolifera
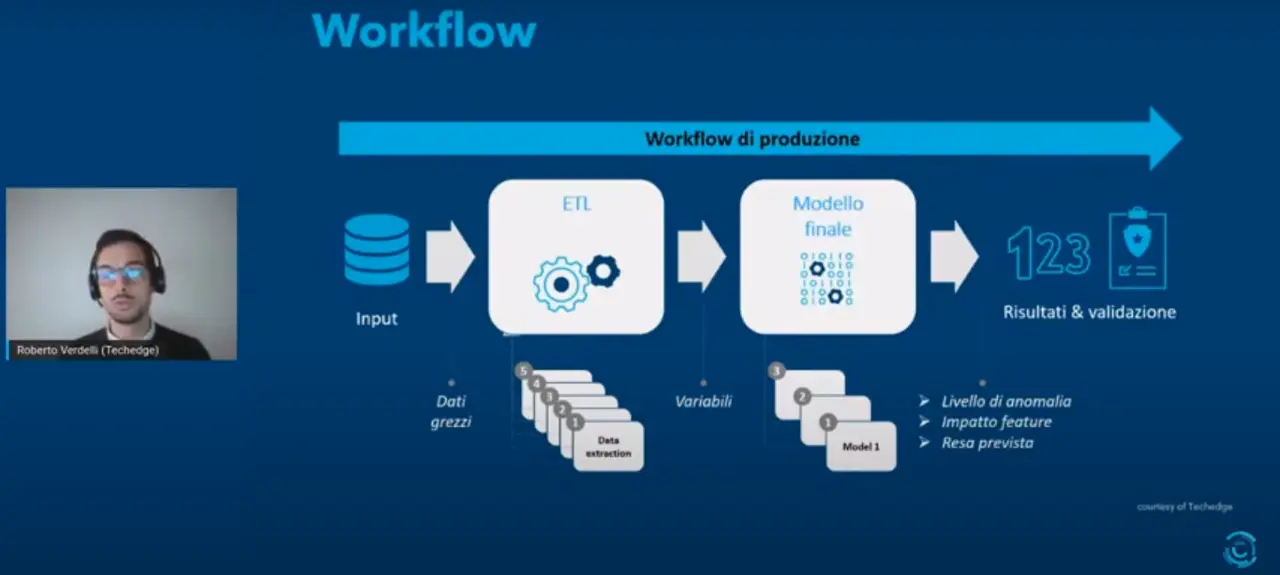
Una delle applicazioni più interessanti è rappresentata dall’anomaly detection, cioè l’identificazione di pattern anomali all’interno dei dati. È il caso portato da Verdelli, relativo all’utilizzo dell’intelligenza artificiale da parte di un cliente nel trasferimento e nello stoccaggio di prodotti petroliferi via oleodotto, navi cisterna e autobotti, lungo tutta la supply chain, quindi sia da deposito a deposito, sia da deposito ai punti vendita finali. A causa delle molteplici sorgenti dati, indispensabile è stato normalizzarle e metterle tra loro in comunicazione, implementando un meccanismo ETL, ovvero extract-transform-load, in grado di interagire con ogni mezzo di trasporto, accentrare le informazioni e collocarle in una repository unica. L’obiettivo è stato quello di individuare i trasferimenti anomali, ovvero quelli potenzialmente affetti da comportamenti scorretti oppure da guasti nei mezzi di trasferimento del materiale. Questi trasferimenti erano tipicamente caratterizzati da basse rese, quindi da una differenza significativa tra prodotto consegnato e prodotto spedito. Quali sono stati i benefici portati dall’AI? Verdelli li spiega così: «Il miglioramento nell’identificazione di queste anomalie, un processo svolto finora manualmente, su un set di dati limitato nonché su strumenti non preposti a questo scopo. La riduzione degli impatti legati alla non compliance ambientale, essendo prodotti petroliferi. E inoltre l’identificazione delle variabili a maggior impatto su questi trasferimenti a bassa resa, permettendo quindi al cliente di focalizzarsi su queste variabili specifiche, per ottimizzare e ridurre queste perdite».
L’obiettivo è stato perseguito mediante un approccio statistico semi-supervised, combinando tecniche di supervised learning e di unsupervised learning. Il modello di unsupervised learning è stato applicato sui dati a disposizione, chiedendogli di identificare, a suo modo di vedere, i pattern anomali all’interno delle osservazioni. Gli algoritmi sono infatti in grado di valutare le caratteristiche statistiche di ogni osservazione, isolando quelle che più atipiche rispetto alle altre, quelle con caratteristiche così particolari da essere considerate anomale. Le osservazioni sono state poi sottoposte all’occhio degli auditor, per distinguerle dai falsi positivi, con una spiegazione prevista per l’anomalia. Parallelamente è stato sviluppato un modello di apprendimento supervisionato, in grado di prevedere la resa di un trasferimento sulla base delle caratteristiche del trasferimento stesso, quindi: mezzo di trasferimento, tipologia e qualità di prodotto, densità, qualità e temperatura di trasferimento. Gli output di questi due modelli sono stati centralizzati all’interno di un terzo modello di classificazione binaria, in grado di produrre uno score di anomalia compreso tra 0 a 100. I trasferimenti con uno score sospetto sono stati poi sottoposti ad analisi più approfondite in modo da capire quali fossero le ragioni della resa imprevista. «Prima di iniziare a valutare concretamente i risultati forniti dal modello, il business ha aspettato sei mesi di accumulo di dati. E per i sei mesi successivi ha fornito feedback sulle anomalie rilevate e verificato come il modello migliorasse le proprie performance. In questo frangente di tempo abbiamo analizzato circa 5.000 trasferimenti, all’interno dei quali sono state identificate 130 anomalie, che non sarebbero state individuate altrimenti», ha raccontato Verdelli.
Le reti neurali per la previsione della domanda
Altra esemplificazione rilevante è stata condivisa da Falcolini, questa volta nell’ambito della predizione su serie temporali, un caso applicato a un’azienda che produce macchine tecnologicamente complesse. Obiettivo: progettare un buon predittore dei valori futuri delle vendite. Risultati: accurati per quanto riguarda i valori aggregati. «Abbiamo utilizzato i dati che riguardavano 12 mesi di domanda dei prodotti di questa azienda, per prevedere i due mesi successivi, spostando questa finestra dal 2002 al 2019 – ha spiegato Falcolini – Prima di essere forniti agli algoritmi, i dati sono stati trattati con varie tecniche, ad esempio di simulazione per introdurre un po’ di rumore, degli effetti di trend, degli effetti di stagionalità». Dopo aver preparato e trasformato i dati, è stata poi effettuata una selezione degli algoritmi da utilizzare, per l’apprendimento del predittore. «Machine learning e intelligenza artificiale sono scienze empirica, bisogna provare-provare-provare per trovare l’opzione ottimale del proprio problema. E infatti così è stato all’interno di questo progetto. Il modello di processo di un progetto di intelligenza artificiale è molto iterativo, non è assolutamente lineare, si torna continuamente sulle cose già fatte», ha aggiunto Falcolini.
Una fase importante è stata infatti quella di cross validation, che ha visto l’utilizzo di un dataset di validazione, oltre a quello di addestramento, per ridurre al minimo i rischi di underfitting e overfitting. Nel primo caso avremmo un modello non sufficientemente complesso per comprendere la soluzione del problema, nel secondo ci troveremmo invece di fronte a un modello non in grado di arrivare a una generalizzazione. Infine, l’ultima fase: quella del deploy del modello, che, addestrato, è stato poi portato in produzione per essere utilizzato. I risultati sono stati interessanti. «Abbiamo visto che la rete neurale, rispetto agli altri algoritmi, ha avuto le performance migliori sulla previsione totale della domanda. In particolare, ha dato performance eccezionali sulla previsione del secondo mese – ha detto Falcolini – È invece interessante notare come la rete neurale inizi ad avere performance peggiori quando si va sul singolo prodotto e non sulla domanda generale. Questo ci dimostra che questo modello può essere ulteriormente specializzato, per poter fare previsioni migliori».
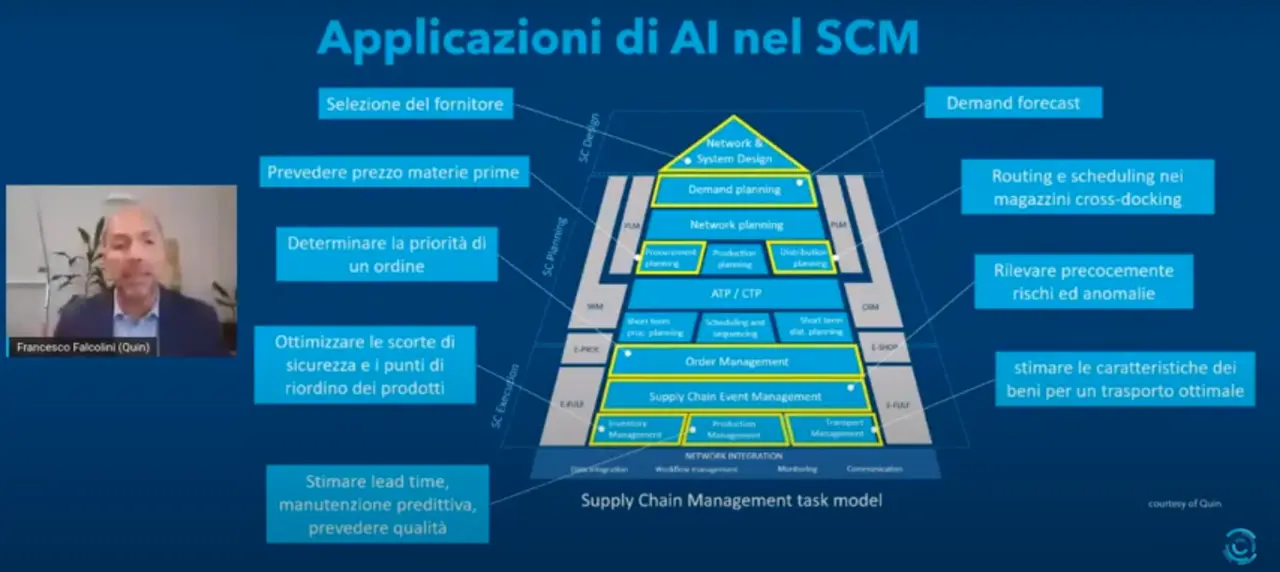
I modelli utilizzati: Random Forest, Isolation Forest, Arima e Reti Neurali
Nel caso di anomaly detection gli algoritmi utilizzati sono stati Random Forest e Isolation Forest. Il primo è stato utilizzato anche nel caso di previsione della domanda, affiancato dall’Arima e dalle Reti Neurali. Per Random Forest si intende un’aggregazione di alberi di decisione, addestrando ogni albero su un dataset diverso. Gli algoritmi di tipo Isolation Forest permettono invece di isolare ciascun punto del dataset sulla base della sua maggiore o minore distanza dagli altri punti. L’Arima, acronimo di Autoregressive integrated moving average, è basato sui dati e su una matematica molto evoluta, con tre componenti principali: l’auto-regressione, dunque correlazione sulla base di dati precedenti, la stazionarietà, cioè serie storiche con deviazione standard costante, media costante, quindi senza effetti di stagionalità e infine la media mobile, correggendo continuamente la previsione con l’errore fatto nella previsione del periodo precedente. Le Reti Neurali ragionano, invece, in maniera totalmente diversa: simulano il comportamento del sistema nervoso umano, che si basa sul neurone.
Il neurone artificiale cerca di replicare il comportamento del neurone umano, fatto da un assone che trasmette un segnale a un nucleo, che poi lo trasferisce attraverso i dendriti ad altre a cellule neuronali. Ci sono quindi degli ingressi, a cui vengono applicati dei pesi, da cui si ricava una sommatoria, che rappresenta l’input di una funzione di attivazione, che simula il nucleo di un neurone che trasferisce parte del segnale di ingresso all’altro neurone a cui è collegato. Il neurone artificiale da solo è già in grado di risolvere problemi semplici: per risolvere problemi più complessi è necessario fare una rete, cioè collegare più neuroni artificiali l’uno con l’altro, così come avviene nelle reti neurali nel nostro sistema nervoso. Reti Neurali multistrato costituiscono il deep learning, aumentando la profondità degli stadi intermedi e quindi la capacità di risolvere problemi sempre più complessi e non lineari. Sebbene se ne parli già dagli anni ‘90, è oggi che registriamo l’esplosione di questa categoria, grazie all’incremento della capacità computazionale, attraverso cui è possibile risolvere con semplicità elaborazioni molto complesse.
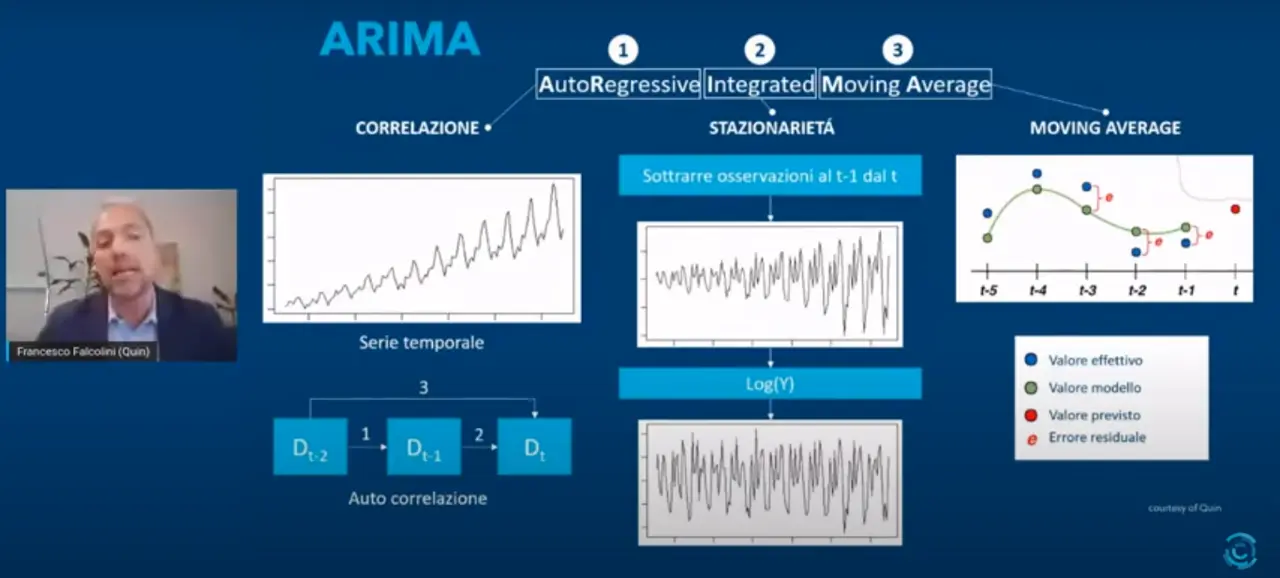
Nuove frontiere: Arimax, modelli ibridi, intelligenza artificiale spiegabile
Una dei rebus ancora non del tutto risolti in questo campo riguarda le variabili esogene, ma i modelli in grado di trattarle iniziano a essere sempre di più. Tra questi c’è l’Arimax, evoluzione dell’Arima, con la X che sta proprio per esogeno. Dunque un Arima che può elaborare la sua previsione non solo basandosi su dati storici, ma anche su dati di natura economica. «Una delle più grandi opportunità che abbiamo in questo momento è la grandissima disponibilità di dati, non solo all’interno delle nostre organizzazioni, ma anche all’esterno, dati che provengono dai social network, dall’IoT oppure dati che riguardano il tempo atmosferico, indicatori macroeconomici, statistici, l’andamento dei mercati, sono tutte informazioni, dati, che possono essere utilizzati per addestrare i modelli, per prevedere la domanda», ha affermato Falcolini. Il deep learning, in questo contesto, diventa particolarmente utile, perché adatto a scoprire correlazioni tra variabili che altrimenti non potrebbero essere evidenziate. «Ma una frontiera che secondo me è veramente interessante, su cui noi ci stiamo impegnando moltissimo, sono i modelli ibridi» ha aggiunto Falcolini.
È difficile che un modello lavori bene in tutte le condizioni, e allora una frontiera della ricerca applicata sarà senza dubbio l’ibridazione, cioè riuscire a creare un modello da un comportamento diverso, sulla base del tipo di domande che si intende prevedere. Ulteriore aspetto, estremamente importante, è l’intelligenza artificiale spiegabile: le reti neurali si comportano al momento come una scatola nera, cioè forniscono una previsione, ma non spiegano il perché della previsione. La spiegabilità dell’intelligenza artificiale sarà fondamentale per poterne avere sempre più fiducia. Diversamente il decisore umano, colui che alla fine assume le decisioni basate sull’intelligenza artificiale, non riuscirà a capire quando la previsione potrebbe essere sbagliata, e dunque migliorare il modello.

La centralità delle persone: tecnologie, metodologie e ricompense
«L’intelligenza artificiale abilita cambiamenti molto rapidi nel modo di lavorare, e risulta a mio parere estremamente importante, durante queste fasi di cambiamento, mettere al centro della rivoluzione le persone. Cioè assicurarsi che le persone della propria organizzazione siano in grado di evolvere alla stessa velocità della tecnologia, e siano ricompensate per farlo», chiarisce Verdelli. I grandi temi afferenti al cambiamento sono dunque principalmente tre: le tecnologie, le metodologie, e le ricompense. Il primo punto attiene a una gestione del dato più puntuale e profonda, attraverso operazioni di centralizzazione e normalizzazione che permettano di avere una completa integrazione delle informazioni all’interno di una repository centrale, che nel lungo periodo diventi il cuore dell’architettura aziendale. Accentrare dati esterni, dati dai sistemi legacy, tutto quanto legato alla IoT permette ai sistemi consumatori – come l’intelligenza artificiale, ma anche la business intelligence tradizionale, e applicazioni più innovative come quelle di digital twin – di avere un unico punto dove risiede la verità del dato», ha aggiunto Verdelli.
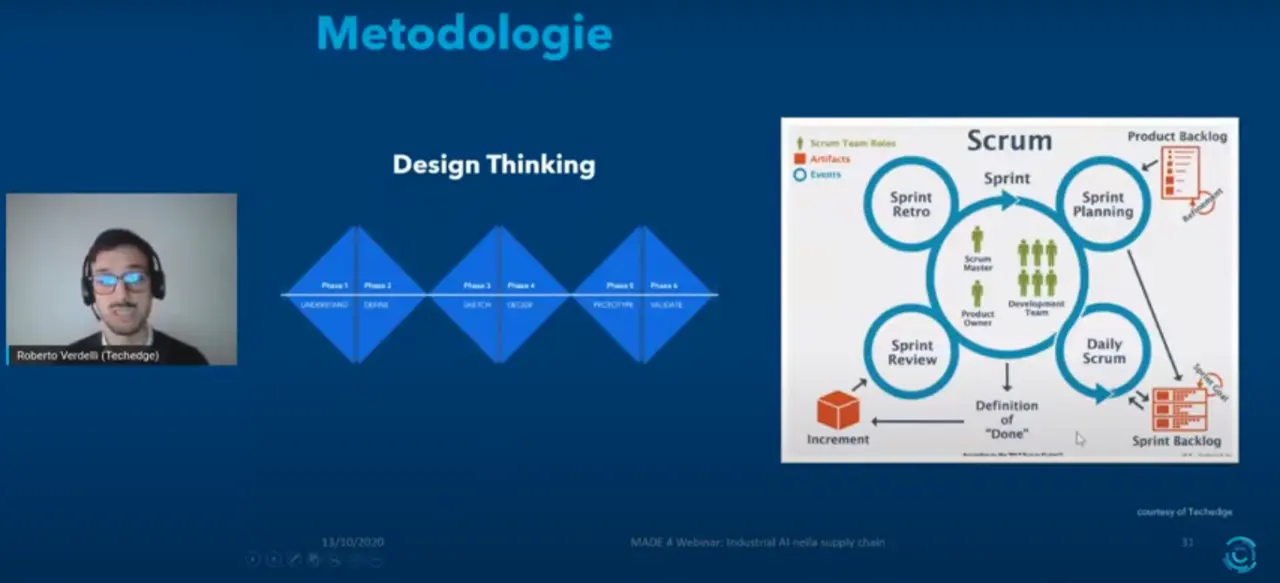
Sul piano delle metodologie, il manager di Techedge ne vede due più efficaci di altre in questo contesto: il design thinking, un approccio brainstorming basato su divergenza e convergenza a fasi alterne, coinvolgendo figure e ruoli eterogenei in azienda, arrivando a una soluzione e una prototipazione veloce, e la metodologia agile, particolarmente in voga poiché tiene a bordo tutti gli stakeholder di progetto, in tutte le fasi progettuali, garantendo un continuo allineamento e quindi il raggiungimento di un risultato finale molto in linea con le aspettative. Infine, va tenuto in debito conto il tema delle ricompense. «Stare al passo con i cambiamenti, con cambiamenti di questo tipo, quindi molto repentini, rivoluzionari, non è semplice. E incentivare le persone a farlo è un must: molte aziende lo fanno con ricompense, inserendo ad esempio nei KPI dei piani aziendali delle sfumature che incoraggino l’utilizzo dei nuovi sistemi digitali, alcuni associano questo tipo di KPI a delle ricompense economiche – conclude Verdelli. – Che chiude così il cerchio, mettendo ogni cosa al suo posto. Tutto sta nelle persone. Il successo lo creano le persone che fanno parte dell’azienda, e accertarsi che stiano al passo con questa rivoluzione è fondamentale».







")

