


L’azienda giapponese ha sviluppato un meccanismo di distribuzione della memoria per i Deep Neural Networks, ampiamente utilizzati per molte applicazioni nel campo dell’intelligenza artificiale (AI)
Che cosa hanno in comune l’analisi nel settore healthcare (ad esempio la rilevazione della retinopatia diabetica), la classificazione e l’analisi delle immagini satellitari, l’elaborazione linguistica naturale, i dati su larga scala relativi a dispositivi IoT, le transazioni finanziarie, i servizi di social network ? La necessità di utilizzare il Deep learning su larga scala. L’apprendimento approfondito, (il Deep learning) appunto, è quel campo di ricerca dell’apprendimento automatico e dell’Intelligenza artificiale che indica un particolare approccio alla progettazione, allo sviluppo, al testing e soprattutto al traning delle reti neurali. Fujitsu ha annunciato novità nell’ambito della tecnologia deep learning, vale a dire lo sviluppo un meccanismo di distribuzione della memoria per i Deep Neural Networks (DNNs).




Ampiamente utilizzato per molte applicazioni nel campo dell’intelligenza artificiale (AI) come il riconoscimento e la classificazione di un discorso e di un oggetto, l’utilizzo avanzato di DNN richiede enormi risorse computazionali, che incidono pesantemente sulle infrastrutture informatiche esistenti. Secondo Fujitsu che ha sviluppato la nuova soluzione nei suoi laboratori europei, il parallelismo del modello impiegato viene utilizzato per distribuire i requisiti di memoria DNN in modo automatizzato, trasparente e facilmente gestibile. Due le conseguenze : la capacità delle infrastrutture esistenti nell’affrontare applicazioni AI su larga scala è notevolmente migliorata ; non occorrono ulteriori investimenti.
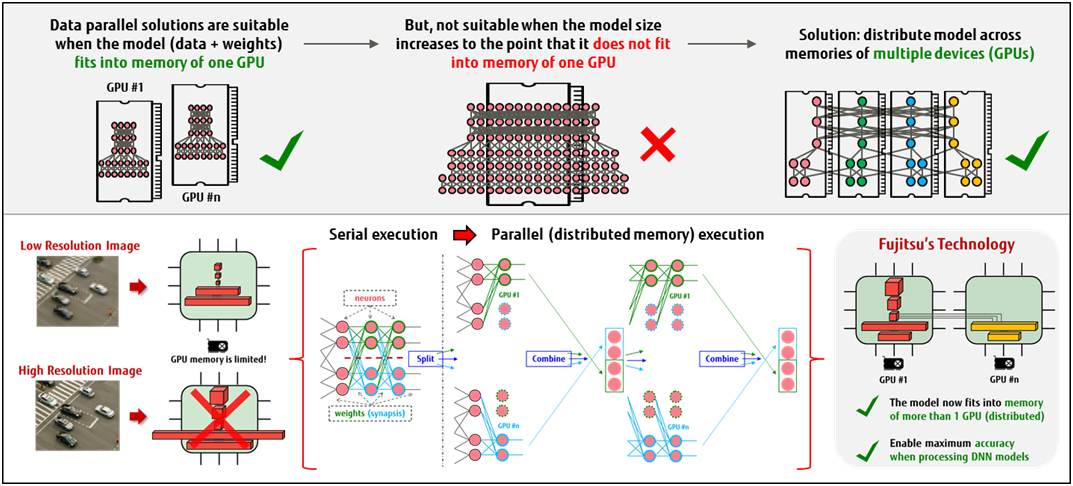
Tsuneo Nakata, CEO dei Fujitsu Laboratories of Europe, spiega: «Negli ultimi anni abbiamo assistito a continue innovazioni tecnologiche che utilizzano acceleratori hardware per supportare l’enorme mole di calcoli necessari per costruire il Deep Neural Networks (DNN) per applicazioni di intelligenza artificiale. L’aumento continuo dei costi di calcolo legati ai DNN è una sfida importante, soprattutto quando la dimensione del modello di DNN crescerà fino al punto di non poter essere caricata nella memoria di un singolo acceleratore.»
«Sono necessarie – prosegue Tsuneo Nakata – reti neurali più ampie e profonde, insieme ad una più raffinata classificazione delle categorie, per affrontare le sfide emergenti di AI. La nostra soluzione agisce proprio in questo modo, distribuendo i requisiti di memoria DNN su più macchine. Con la nostra tecnologia è possibile ampliare le dimensioni delle reti neurali che possono essere elaborate da più macchine, consentendo lo sviluppo di modelli DNN più accurati e su larga scala.»
Alla distribuzione ottimizzata della memoria la tecnologia by Fujitsu attende perché trasforma gli strati di reti neurali, arbitrariamente progettate, in reti equivalenti in cui alcuni o tutti i suoi strati sono sostituiti da una serie di sotto-strati più piccoli. Queste ultime serie sono progettate per essere funzionalmente equivalenti agli strati originali, ma sono molto più efficienti da eseguire dal punto di vista computazionale. L’azienda sottolinea che, poiché gli strati originali e quelli nuovi derivano dal medesimo profilo, il processo di formazione del DNN ‘trasformato’ converge a quello del DNN originale senza prevedere ulteriori costi.








